* [바닥부터 배우는 강화학습] 도서를 읽고 정리한 글입니다
앞으로 이야기는 어떤 문제의 상황이 주어졌을 때 MDP의 형태로 만들어서 MDP를 풀어 문제를 해결해 나가는 방법을 논의할 것이다.
여기서 MDP를 푼다는 것은 MDP 형태 (S, A, P, R, \( \gamma \) )가 주어졌을 때 아래 2가지 문제를 해결하는 것을 의미한다.
(1) Prediction : 에이전트가 액션을 선택하는 방법에 대한 정책함수 \( \pi \) 가 주어졌을 때 각 상태의 밸류를 평가하는 문제
(2) Control : 최적 정책 \( \pi^{*} \)를 찾는 문제
좀 더 자세히 살펴보기 위해 그리드 월드 예시를 살펴본다.
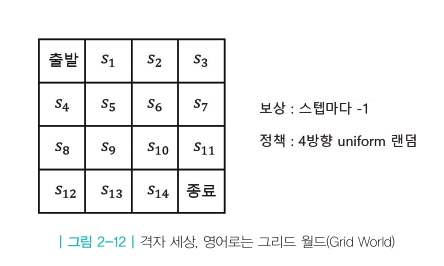
- 먼저 그리드 월드상에서 Prediction을 설명한다.
Prediction을 하려면 당연히 에이전트가 액션을 취하는 방법인 정책 \( \pi \)가 주어져야 한다.
처음에는 간단하게 모든 상태에서 4방향으로 랜덤하게 움직이는 정책으로 정한다.
수식으로 표현하면 아래와 같다
$$ A= \left [ 동쪽으로 이동, 서쪽으로 이동, 남쪽으로 이동, 북쪽으로 이동 \right ] $$
$$ \pi(동 \vert s) = 0.25, \pi(서 \vert s) = 0.25 , \pi(남 \vert s) = 0.25, \pi(북 \vert s) = 0.25 $$
이런 MDP 모델에서 \( s_{11} \)의 상태 가치 \( \nu_{\pi} (s_{11}) \)의 값은 얼마일까?
이것이 Prediction 문제이고 해당 상태의 밸류(상태가치함수)를 예측(계산)하는 것이 목적이다.
수식으로 표현하면 앞에서 언급된 상태가치함수이다.
$$ \nu_{\pi} (s_{11}) = \mathbb{E} \left [ G_t \vert S_t = s_{11} \right ] $$
\( s_{11} \)에서 취할 수 있는 액션이 4가지 이므로 그에 따라 이동경로도 여러 경우가 나온다.
예를 들면,

각각의 이동경로는 에피소드 라고 하며
상태가치함수를 계산하기 위해서는 위의 에피소드의 각각의 경우에 대해 발생확률과 리턴값을 얻어내어 확률과 리턴값을 곱하여 기댓값을 계산해야 한다.
하지만 복잡한 환경에서는 모든 에피소드를 찾아내는 것이 불가능하므로 실제로 계산시에는 언급한 것처럼 계산하지는 않는다.
실제 계산방식은 뒤에서 설명이 이어진다. 여기서는 개념만 이해하고 넘어가도록 한다.
정리하면, Prediction 문제는 주어진 상태에서의 상태가치함수 계산을 통해 상태의 가치를 계산해 내는 문제이다.
- Control 문제
Control의 목적은 최적의 정책 \( \pi^{*} \)를 찾는 것이다.
복잡한 MDP 모델 상에서 최적의 정책을 찾는 것은 매우 어려운 일이며 이를 위해서 강화학습을 진행하게 된다.
최적의 정책 \( \pi^{*} \)를 따를 때의 가치 함수를 최적가치함수 라고 하며 \( \nu^{*} \)라고 표기한다.
만일, 최적의 정책 \( \pi^{*} \) 와 최적가치함수 \( \nu^{*} \)를 찾았다면 주어진 MDP를 풀었다고 한다.
다시 언급하면, 이후에는 Prediction 과 Control에 대한 내용을 중심으로 다루게 될 것이다.
'인공지능 > 바닥부터 배우는 강화학습' 카테고리의 다른 글
| ch 04. MDP를 알 때의 플래닝 (0) | 2021.06.02 |
|---|---|
| ch 3. 벨만 방정식 (0) | 2021.05.29 |
| ch 2-3 마르코프 결정 프로세스(Markov Decision Process)-MDP (0) | 2021.05.25 |
| ch2-2. 마르코프 결정 프로세스(Markov Decision Process-MDP)-마르코프 리워드 프로세스 (0) | 2021.05.23 |
| ch2-1. 마르코프 결정 프로세스(Markov Decision Process-MDP)-마르코프 프로세스 (0) | 2021.05.22 |