* [바닥부터 배우는 강화학습] 도서를 읽고 정리한 글입니다
보상과 전이확률을 모르는 상황을 모델프리( Model - free) 라고 부른다.
모델 프리 상황에서 정책 \( \pi \)가 주어졌을 때 밸류 평가 방법 즉, Prediction 문제를 푸는 2가지 방법
몬테카를로와 Temporal difference 를 소개한다.
작은 모델 MDP에 대해 다루기 때문에 이전 챕터에서 사용했던 테이블 룩업 방법론을 적용하여 문제를 풀어간다.
1. 몬테카를로 학습
몬테카를로 방법론 - 직접 측정하기 어려운 통계량을 구하고자 할 때 여러 번 샘플링하여 그 값을 가늠하는 기법

위 공식은 상태가치함수의 정의이다.
공식을 풀이해보면 정책 \( \pi \)가 주어진 상황에서 t 시점의 상태 \( s_t \)의 밸류는 t 시점의 리턴의 기댓값이다.
리턴을 얻어내기 위해 직접 에피소드를 종료시점까지 실행하여 리턴값을 얻어내고 이 과정을 반복하여 얻어낸 리턴의 평균을 냄으로 리턴 기댓값을 계산해 내는 것이 몬테카를로 학습의 중요 개념이다.
바둑게임을 예시로 들어보면,
임의의 시점에 바둑판의 상황을 캡쳐해놓고 이 상황이 얼마나 좋은 상황인지 밸류를 평가하려면 실제로 그 상황에서 부터 게임 종료까지 진행해보고 승패 여부에 맞게 보상을 주고 이 과정을 수만 번 반복함으로 리턴 기댓값을 계산해 냄으로 캡쳐한 상황의 밸류를 평가할 수 있다.
1.1 몬테카를로 학습 알고리즘

보상과 전이확률을 모르는 그리드 월드를 이용하여 몬테카를로 학습 알고리즘을 살펴본다.
실제로 보상은 -1, 전이확률은 100% 라고 정해놓고 그 내용을 에이전트가 모르는 상태에서 몬테카를로 학습을 진행한다고 가정한다.
(1) 테이블 초기화

위 그림의 오른쪽 테이블에서 보이는 것처럼 각 상태별로 N(s)와 V(s) 2개의 값이 필요한데
N(s)는 학습하는 동안 해당 상태를 방문한 횟수 이며,
V(s)는 해당 상태 방문시 마다 얻게된 리턴 누적 합을 의미한다.
초기에는 각 상태별로 2값을 모두 0으로 셋팅한다.
(2) 경험쌓기
에이전트는 주어진 \( \pi \) 정책하에 \( s_0 \) 상태부터 시작하여 종료상태까지 액션과 그에 따른 보상을 받으면서 에피소드를 진행해 나간다. 이를 기호로 표기하면 아래와 같다.
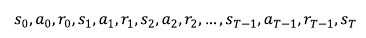
이렇게 하나의 에피소드가 종료되면 각 상태에 대한 리턴은 아래와 같이 계산할 수 있다.

감마 \( \gamma \)와 보상은 실행해 나가면서 에이전트가 알게된 숫자값이다. 결국 각 상태별 리턴은 숫자값이 되는 것이다.
(3) 테이블 업데이트

위 그림의 경로로 하나의 에피소드가 끝난 후 (2)에서 제시한 수식으로 상태별 리턴값을 계산하여
상태별 N(s)와 V(s)값을 업데이트 한다. (위 그림 우측테이블)
(4) 상태 밸류 계산
경험쌓기와 테이블 업데이트를 충분히 반복한 후 각 상태별로 리턴(V(s))의 평균값을 계산하면 그 값이 상태 밸류가 된다.

(5) 조금씩 업데이트하는 버전
(4)번 까지의 방법은 에피소드를 충분히 반복한 이후 (예를 들면, 10만번 반복 실행) 밸류를 계산할 수 있었다.
이번 방법은 하나의 에피소드가 끝날때마다 밸류를 조금씩 업데이트 시켜주는 방법이다.
방법은 아래 공식과 같이 \( \alpha \) 라는 개념을 추가하여 기존 값에 새로 계산된 리턴값을 얼마의 비율로 섞어줄지를 지정할 수 있도록 한 것이다.

이렇게 되면 N(s)를 저장해 둘 필요가 없다.
위 공식을 조금 변형하면 아래 식이 된다. 이후에 몬테카를로 학습에서는 아래의 식을 사용한다.





2. Temporal Difference 학습
MC 학습(몬테카를로 학습)은 최소한 하나의 에피소드가 끝나야 밸류를 업데이트할 수 있는 구조이다.
하지만 실제 세계에서는 종료 조건이 명확하지 않은 MDP도 많다.
이처럼 종료하지 않는 MDP 에서 밸류를 구할 수 있는 방법이 Temporal Difference 학습방법이다.
Temporal Difference의 기본 개념은 아래와 같다.
"추측을 추측으로 업데이트 하자!!"
한 스텝이 지나고, 조금이라도 시간이 흐르면 좀 더 정확한 추측을 할 수 있게 되는 것이고 이를 이용하여 이전 스텝의 밸류를 업데이트 활용하는 방식이다.
2.1 이론적 배경

위 공식은 벨만 기대 방정식 0단계 수식이다.
위 공식을 풀이해보면,
\( r_{t+1} + \gamma \nu_{\pi}(s_{t+1}) \)을 여러 번 뽑아서 평균을 내면 그 평균은 \( \nu_{\pi} (s_t) \)에 수렴한다는 의미이고,
\( r_{t+1} + \gamma \nu_{\pi}(s_{t+1}) \)을 풀이해보면,
\( s_t \) 상태에서 받게 되는 보상 \( r_{t+1} \)과 다음 상태( \( s_{t+1} \)의 밸류를 합한 값을 의미한다.
여기서 \( \nu_{\pi}(s_{t+1}) \) 값이 다음 스텝으로 이동 시 상태밸류 값이고 이것은 사실 에피소드가 끝나기 전 까지는 예상치라고 볼 수 있을 것이다.
이전에도 언급했듯이 , 반복적으로 수행하다 보면 위 예상치에 보상을 더하기 때문에 점차 실제 상태밸류에 수렴해간다
여기서 \( r_{t+1} + \gamma \nu_{\pi}(s_{t+1}) \) 값을 "TD 타깃" 이라고 부른다.
MC학습에서는 각 상태별 리턴을 여러 개 모아 평균을 내어 밸류를 측정했듯이,
TD에서는 TD타깃 \( r_{t+1} + \gamma \nu_{\pi}(s_{t+1}) \)을 여러 개 모아 평균을 내어 밸류를 측정한다.
2.2 TD 학습 알고리즘
MC 학습과 동일한 조건에서 TD학습 알고리즘을 설명한다.
(1) 초기화

에이전트를 \( s_0 \) 상태부터 경험을 쌓게 한다.
하나의 에피소드 경로는 아래와 같다

이런 상태에서 TD학습이 MC학습과 차이나는 부분은 2가지이다.
1) 다음 스텝으로 이동한 직후 이전 스텝의 밸류를 아래 수식으로 업데이트 해준다.

이전의 MC 학습 시 공식과 비교하면,

2) MC학습에서 리턴값을 이용했던 위치에 TD타깃이 대입되었다고 보면 된다.
위 방법으로 하나의 에피소드에 수식을 적용해보면

위 과정을 에피소드를 반복적으로 수행하면서 진행해나가면 테이블에 상태밸류값은 수렴하게 된다.

3. MC (몬테카를로) & TD 비교
3.1 학습시점 측면
MC는 Episodic MDP (종료가 있는 MDP) 에서만 적용할 수 있다.
TD는 Episodic MDP 와 Non-Episodic MDP (종료가 없는 MDP) 에서도 적용할 수 있다.
따라서 모든 종류의 MDP에서 적용이 가능하다는 측면에서 TD가 좀 더 낳은 방법이다.
3.2 편향성(Bias) 측면

위 공식은 MC의 근간이 되는 수식과 TD의 근간이 되는 수식이다.
MC의 밸류는 리턴들을 여러 개 모아 평균을 내는 방법론으로 샘플이 모일 수록 실제밸류에 반드시 수렴하게 된다.
즉, 편향되지 않는 안전한 방법이다.
TD는 현재의 밸류 추측치를 다음 스텝의 밸류 추측치로 업데이트 해주는 방법이다.
위 벨만 기대 방정식 공식에서 사용되는 것은 \( \nu_{\pi} (s_{t+1}) \) 이지만 실제 사용되는 값은 V(\(s_{t+1}\)) 이다
\( \nu_{\pi} \) : 정책 \( \pi \)의 실제 가치를 의미하며
V : 학습과정에서 업데이트하고 있는 테이블 안에 쓰여있는 값으로 \( \nu_{\pi} \)와 같아지기를 바라는 값
따라서

이고, 현실에서 사용되는 TD타깃 \( r_{t+1} + \gamma V(s_{t+1}) \)는 편향되어 있다.
편향의 의미를 해석하자면, TD타깃은 샘플을 무한히 모아서 업데이트해도 실제 가치에 다가간다는 보장이 없다는 뜻이다. 하지만 몇 가지 조건을 붙이면 실제로 의미있게 동작한다. 그 부분은 뒤에서 다시 언급한다.
데이터의 편향성 측면에서 보았을 때는 편향되어 있지 않은 MC학습법이 우세하다.
3.3 분산 (변동성)(Variance) 측면
- MC 학습 과정에서 나오는 리턴값은 변동성이 크다
- TD학습과정에서 나오는 TD타깃은 변동성이 작다
1) MC 학습 과정에서 나오는 리턴값은 변동성이 크다
MC학습에서 하나의 리턴값을 얻으려면 하나의 에피소드가 종료되어야 하며 하나의 에피소드 과정에는 많은 확률적 과정이 들어가 있다. 쉽게 말해 수많은 동전 던지기가 실행되면서 에피소드가 진행된다는 의미이다.
따라서 그만큼 리턴 결과 값은 변화가 클 수 있다는 것이다.
2)TD학습과정에서 나오는 TD타깃은 변동성이 작다
TD학습과정에서 밸류값을 업데이트 하기 위해서는 한 스텝만 이동하면 되므로 확률적 과정이 상당히 적게 들어간다.
액션 선택과정과 액션선택 후 다음 상태로 전이하는 과정, 이렇게 2과정이 확률적 과정이라고 보면 된다.
따라서 그만큼 결과값의 변동성이 MC 보다는 작을 수 있다는 것이다.
3.4 종합
요즘 강화학습은 종료상태가 있건 없건 사용가능한 TD학습을 많이 적용하고 있다.
4. MC와 TD의 중간 성격을 지닌 학습방법
4.1 n스텝 TD
이 방법은 여러 스텝을 진행하여 각 스텝별 보상을 받은 후 그 다음스텝의 V(\(s_{t+n}\)) 값을 이용하여 밸류를 계산할 수 있다는 개념이다.
이 개념을 수식으로 표현하면 아래와 같다.

N을 무한대로 했을 경우 식은 아래와 같다.

이 경우 결국 리턴계산식과 동일하다.
TD 학습방법에서 n이 무한대인 특수한 경우가 MC라는 것을 알 수 있다.
이 내용을 하나의 스펙트럼으로 표현하면 아래와 같다.

위 그림에서 좌측 끝단은 TD-zero (N=1인 경우의 TD타깃을 이용하여 업데이트하는 방법론),
우측 끝단은 MC 학습을 의미한다.
N이 커질수록 MC 성격에 가까워지게 된다.
즉, 추측값인 TD타깃의 값이 작아지고 보상의 비중이 늘어가게 되어 결국 편향성은 줄어들고, 확률적 과정이 점차 많이 포함되므로 변동성은 점차 커지게 된다.
결국, TD 학습을 적용할 때 N을 얼마로 할 것인지가 주요한 결정이 될 것이다.
유명한 A3C 알고리즘 논문은 N = 5로 하여 적용하였다.
'인공지능 > 바닥부터 배우는 강화학습' 카테고리의 다른 글
| ch07. Deep RL 첫걸음 (0) | 2021.06.16 |
|---|---|
| ch06. MDP를 모를 때 최고의 정책 찾기 (0) | 2021.06.15 |
| ch 04. MDP를 알 때의 플래닝 (0) | 2021.06.02 |
| ch 3. 벨만 방정식 (0) | 2021.05.29 |
| ch 2-4. 마르코프 결정 프로세스(Markov Decision Process) - Prediction과 Control (0) | 2021.05.26 |