* [바닥부터 배우는 강화학습] 도서를 읽고 정리한 글입니다
이번 장부터는 강화학습과 신경망을 접목시키는 방법에 대해서 설명한다.
* 액션을 정하는 기준에 따라 에이전트를 3종류로 나눌 수 있다.
1. 가치기반 에이전트 - 가치함수에 근거하여 엑션을 선택한다. (정책함수가 따로 없는 경우도 있다.)
SARSA 나 Q러닝에서 학습했던 에이전트가 가치기반 에이전트들이다.
2. 정책기반 에이전트 - 정책함수 \( \pi (a \vert s) \)를 보고 직접 액션을 선택한다.
가치함수를 따로 두지 않으며 따라서 가치를 평가하지도 않는다.
3. 액터-크리틱 - 가치함수와 정책함수 모두 사용한다.
이번 장에서는 신경망을 이용하여 가치 기반 에이전트를 학습하는 내용을 다룬다.
8.1 밸류 네트워크의 학습
우선, 정책\( \pi \)가 고정되어 있을 때, 신경망을 이용해 \( \nu_{\pi}(s) \)를 학습하는 방법에 대해 살펴본다.

위 그림과 같은 신경망으로 이루어진 가치함수 \( \nu_{\theta}(s) \)가 있다.
이 신경망을 "밸류 네트워크" 라고 부른다.
\( \theta \)는 신경망의 파라미터를 의미하며
신경망에 포함된 파라미터가 100만개라면 \( \theta \)는 길이가 100만인 벡터를 말한다.
손실함수는 아래와 같이 정의된다.

해당 손실함수를 최소화 하는 방향으로 \( \theta \)를 업데이트하도록 학습하면 된다. 여기서 하나 생각해야 할 것이 어떤 S에 대해서 손실함수의 최소화 처리를 할 것인가 ?
현재 규모가 큰 MDP 라는 전제조건이 있으므로 주어진 MDP 상에 존재하는 모든 상태 S에 대해 최소화처리는 쉽지 않다.
그래서 손실함수를 약간 변형하여 정의한다.

기댓값 연산자는 정책함수 \( \pi \)를 이용해 방문했던 상태 s에 대해 손실함수를 계산하라는 의미이다.
이 값은 실제로 계산할 수 있다. 정책 \( \pi \)를 이용해 데이터를 모으고 그 데이터를 이용해 학습하면 된다.
정의된 손실함수 \(L(\theta)\) 를 \( \theta \)에 대해 편미분을 통해 그라디언트를 계산한다.
미분 결과식은 아래와 같다.

위 식은 \( \nu_{true}(s) \)는 현재 모델에 존재하는 실제 상수값이므로 다음 공식을 이용해 유도된다.

수식을 간소화하기 위해 상수2는 생략되었는데 해당 값은 스텝사이즈 역할을 하게 되므로 추후 \( \alpha \)값을 이용해 조절된다.
위의 미분결과식을 실제 계산하기 위해서는 정첵\( \pi \)를 근거로 액션을 취하는 에이전트를 통해 상태 s 샘플을 뽑는다.
충분히 반복해서 실행하면서 아래 우변 수식을 계산하여 평균을 내면 결국 좌변 즉 손실함수의 \( \theta \)에 대한 미분에 근사한 결과를 갖게 된다.

손실함수의 \( \theta \) 에 대한 미분을 계산했다면 그 결과값을 이용해서 \( \theta \)값을 아래의 수식을 이용해 업데이트 한다.

이 과정의 반복을 통해 손실함수가 최소화가 되는 \( \theta \)를 구할 수 있게 된다.
다시 말해, 실제 밸류함수에 근사한 밸류 함수를 구할 수 있게 되는 것이다.
여기서 문제는 \( \nu_{true}(s) \)를 알 수 없다는 것이다. 즉 정답을 모르니 신경망을 통한 학습을 할 수 없게 되는 것이다.
이러한 경우 이전 챕터에서 언급했던 MC 방법의 리턴과 TD 방법의 TD타깃을 활용할 수 있다.
1. 첫번째 대안 : 몬테카를로 리턴
챕터 5 에서 몬테카를로 방식을 이용해 테이블의 t 시점의 밸류값을 업데이트 하는 수식이 아래와 같다.
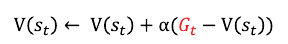
이 수식에도 정답자리에 \( G_t \)를 사용했는데 이유는 가치함수의 정의가 리턴 \( G_t \)의 기댓값이기 때문이다.
동일한 이유로 손실함수의 \( \nu_{true}(s) \) 대신에 \( G_t \)를 사용할 수 있으며 식은 아래와 같다.
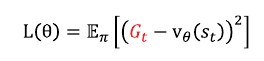
따라서 \( \theta \)업데이트식은 아래와 같다.
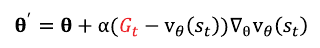
충분히 반복적으로 에피소드를 실행해가면서 한 에피소드가 끝날 때마다 모인 샘플상태 s들의 리턴값을 활용해 손실함수의 파라미터 \( \theta \)를 업데이트해 나간다.
전체적인 강화학습과정은 MC의 특성을 그대로 가지고 있게 된다. 즉 하나의 에피소드가 끝나야 업데이트가 진행되므로 실시간 업데이트는 불가능하며, 리턴의 분산이 크다는 점 등이 특성이다.
2. 두번째 대안 : TD 타깃
앞에서 언급한 \( G_t \) 자리에 TD타깃을 대입하면 된다. 따라서 손실함수는 아래와 같다.

또한 파라미터 업데이트 식은 아래와 같다.
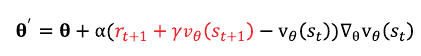
업데이트 식에서 TD타깃 부분은 상수이다. 업데이트할 당시의 \( \theta \)파라미터 값을 이용해 \( \nu_{\theta}(s_{t+1}) \)값이 계산되어지며 상수가 되므로 미분시 0이 되면서 미분 대상에서 제외된다.
8.2 딥 Q러닝
가치기반 에이전트는 명시적 정책 \( \pi \)가 따로 없다.
대신, 액션-가치함수 q(s,a)를 이용해 밸류를 계산하고 각 상태에서 q가 가장 높은 액션을 선택하는 정책을 사용하게 된다.
챕터6의 Q러닝에서 이미 언급한 내용이다. 다만 전제조건이 규모가 큰 MDP라는 것으로 변경되었다. 따라서 테이블 기반 방법론으로 Q값을 저장 및 업데이트 할 수 없으며 신경망을 이용해서 q(s, a)표현한다.
1. 이론적 배경
벨만 최적 방정식과 이를 이용한 테이블 업데이트 수식은 아래와 같다.

업데이트 수식의 빨간 부분을 정답 부분이라고 볼 수 있다.
따라서 손실함수는 아래와 같이 정의된다.

해당 손실함수의 미분을 진행한 후 파라미터 \( \theta \) 업데이트 수식은 아래와 같다.

이 수식을 이용해서 \( \theta \) 파라미터를 계속 업데이트 하면 \( Q_{\theta}(s,a) \)는 점점 최적의 액션-가치함수 \( Q_{*}(s,a)\) 에 가까워질 수 있다.
설명한 손실함수 결과값 최소화 처리과정을 전체 강화학습과정에 함께 넣어 학습절차를 아래 설명한다.

환경에서 실제로 실행할 액션을 선택하는 부분은 3-A,
TD 타깃 값을 계산하기 위한 액션을 선택하는 부분은 3-C 이다.
( 3-C에서 선택한 액션은 실제로 실행되지 않으며 업데이트를 위한 계산에만 사용된다 => Off-policy 학습 특성 =>
실행할 액션을 선택하는 행동 정책은 \( \epsilon \)- greedy \( Q_{\theta} \)(3-A)단계 이고, 업데이트시 사용되는 정책은 greedy \(Q_{\theta} \) (3-C) 로 서로 다르다 )
파이토치로 구현할 때 기억해야 할 부분이 있다.
3-D 단계는 실제 구현시 손실함수만 정의해주고 손실함수에 대한 minimize 함수를 호출해주면 파이토치 라이브러리가 알아서 그라디언트를 계산하여 \( \theta \) 파라미터를 업데이트 해준다.
2. 익스피리언스 리플레이와 타깃 네트워크
Deep Q러닝을 기본으로 하는 DQN 알고리즘에서 안정적인 학습과 성능을 위해 추가로 사용된 2가지 방법론이 있다.
2-1 익스피리언스 리플레이

"겪었던 경험을 재사용하면 더 좋지 않을까?" 질문에서 시작된 아이디어이다.
경험은 에피소드를 의미하며 에피소드는 여러 개의 상태전이로 구성된다.
t시점에서의 상태전이는 아래와 같이 표현할 수 있다.
$$ e_t = ( s_t, a_t, r_t, s_{t+1}) $$
해석하자면 "상태 \(s_t\)에서 액션 \(a_t\)를 선택했더니 보상 \(r_t\)를 받고 다음 상태 \(s_{t+1}\)로 이동했다"는 의미이다.
이렇게 하나의 상태전이를 하나의 데이터로 볼 수 있다.
이런 상태전이 데이터를 최근기준으로 n개를 버퍼에 저장해두고 학습할 때 이 버퍼에서 정한 개수만큼 임의로 상태전이 데이터를 뽑아서 학습에 사용한다는 것이 리플레이 버퍼 개념이다.
이 방법은 상태전이 데이터를 재사용함으로 효율성을 올려주고, 랜덤하게 상태전이 데이터를 추출하면서 데이터 사이 상관성을 줄여주어 결과도 좋게 나온다(?)고 주장 한다
이 방법은 off-policy 알고리즘에만 사용할 수 있다.
리플레이 버퍼에 저장되어 있는 상태전이 데이터들은 과거의 정책에 따라 생성된 데이터이고 그것을 이용해 현재의 타깃정책을 개선하려고 하기 때문이다.
2-2 별도의 타깃 네트워크

Deep Q 러닝에서 손실함수 \(L(\theta)\)의 의미는 정답과 추측 사이의 차이이며, 이 차이를 줄이는 방향으로 \(\theta\)가 업데이트 된다.
자세히 보면, 위그림에서 보듯 Q 러닝의 정답부분은 \( \theta\)에 의존적이다. 학습하면서 신경망을 통해 \(\theta\)가 업데이트 되고 결국 정답에 해당하는 값이 변경된다. 이처럼 신경망 학습과정에서 정답이 변하는 것은 학습 성능을 떨어뜨린다.
이 문제점을 해결하기 위해 타깃 네트워크 방법이 등장했다.
정답을 계산할 때 사용하는 타깃 네트워크와 학습을 받고 있는 Q 네트워크로 구성된다.
그리고 정답을 계산할 때 사용되는 타깃 네트워크의 \(\theta\) 파라미터들을 일정 기간 변경하지 않는다 (얼린다).
=> 얼린 파라미터를 \(\theta_i^{-}\)라고 표기한다.
그 사이 Q네트워크의 \(\theta\)는 계속 업데이트를 진행한다.
일정주기, 예를 들면, Q네트워크에서 1천번 \(\theta\)를 업데이트 시킨 후 타깃네트워크의 \(\theta_i^{-}\)에 현재 시점의 Q네트워크의 \(\theta\)를 업데이트 시킨다.
이 방법을 적용시 성능이 대폭 개선되었음을 확인할 수 있었다.
3. DQN 구현
아래 그림과 같이 카트 위에 막대를 세워놓고 카트를 잘 움직여서 넘어지지 않도록 균형을 잡는 카트폴 문제를 직접 구현해본다.

이 문제에서 카트를 에이전트로 볼 수 있으며 이 경우 에이전트의 액션은 좌로 이동, 우로 이동 2가지로 구성된다.
각 스텝(?) 마다 +1의 보상을 주는 것으로 하여 가능한 오래 균형을 잡으면, 즉 목적에 부합되면 보상이 최대가 되도록 한다.
종료시점은 막대가 수직으로부터 15도 이상 기울어지거나 카트가 화면 끝으로 나가면 종료되는 것으로 한다.
카트 상태 S는 아래와 같은 항목으로 구성된 길이 4인 벡터이다.
S=(카트의 위치정보, 카트의 속도정보, 막대의 각도, 막대의 각속도)
위의 조건 하에 구현을 진행한다.

gym은 OpenAI GYM 라이브러리를 의미한다.
collections 라이브러리의 deque 자료구조에 선입선출 특성을 이용해서 리플레이 버퍼 구현한다.


ReplayBuffer 클래스는 크게 보면 put함수와 sample함수로 구성된다.
put함수는 최신 상태전이 데이터를 버퍼에 넣어주는 함수이며,
sample함수는 버퍼에서 배치크기 (여기서는 32)만큼 데이터를 뽑아서 미니배치를 구성하는 함수이다.
그리고 하나의 데이터는 (s, a, r, s_prime, done_mask)로 구성된다.
done_mask는 현재상태의 종료여부로 종료는 0, 나머지 상태에서는 1의 값을 갖는다.
ReplayBuffer 는 collections.deque 클래스를 이용했기 때문에 버퍼가 꽉 찬 상태에서 데이터가 더 들어오면 자동으로 가장 먼저 들어온 데이터가 버퍼에서 밀려난다.

위에서 구현된 Q네크워크의 구조는 아래 그림과 같다.

질문]
Q 네트워크 결과로 크기 2인 벡터값이 나오도록 구성하였는데 왜 크기가 2인 벡터일까?
밸류가 나와야 하지 않나? 즉, 스칼라값이 나와야 하지 않나?
=> 벡터의 0번째는 좌로이동시 q밸류값, 1번째는 우로이동시 q밸류값을 의미하는 것으로 판단되며 만일 0번째 값이 크다면 좌로 이동하는 액션의 밸류가 큰 것으로 판단하여 좌로 이동 액션을 선택하게 된다. 1번째 값이 크다면 그 반대의 경우로 판단할 수 있을 것이다.

하나의 에피소드가 끝날때마다 train함수가 호출되며 함수 내부에서는 버퍼에서 10개의 미니배치(한개당 32개의 데이터로 구성)를 얻어와서 학습을 진행한다.
train함수내부 설명
(1) s,a,r,s_prime,done_mask=memory.sample(batch_size) =>
소스 초기에 batch_size=32로 셋팅했으므로 결과 행렬들은 32 크기로 묶어서 리턴된다.
예를 들어, 상태 s는 크기가 4인 벡터로 정의했으므로 sample함수를 통해 리턴되는 s는 32 * 4 크기의 행렬로 리턴된다.
(2) q_out = q(s) =>
q(s)는 Qnet.forward함수 호출하여 결과로 구성한 신경망의 Output 을 리턴한다.
앞에서 언급했듯이 구성한 신경망의 결과로 크기가 2인 벡터가 나오게 되므로 미니배치 32 * 4의 input이 들어갔으므로 결과로 나오는 Output은 32 * 2 행렬이 된다.
결과값의 의미는 좌로 이동시(0) / 우로 이동시(1) 액션밸류 q를 의미한다.
(3) q_a = q_out.gather(1, a) =>
해당 소스를 이해하려면 먼저 gather함수의 동작을 이해해야 한다.
A.gather 함수는 간단히 말하면, A행렬 중에서 복수개의 특정 위치의 값들을 한번에 추출해주는 역할을 한다.
복수개의 특정위치의 값들을 추출하려면 복수개의 특정위치 정보를 gather함수에게 넘겨주어야 하는데 이 부분을 좀 더 설명한다.
예를 들어 설명한다.
A => [[10,11,12],[13,14,15],[16,17,18]]의 (3 * 3 ) 인 2차원 텐서라고 가정하자.
gather함수를 이용해서 텐서의 원소 중 10과 12 , 14와 13, 17과 18값을 추출하고 싶을 때 원소 위치를 지정하는 방법은 아래와 같다.
B => [[0, 2],[1, 0],[1,2]]
이렇게 (2*2) 인 텐서를 구성하고 첫번째 줄의 원소에는 A텐서 첫번째 줄에서 뽑고 싶은 원소 index를 기록한다.
10값이 첫번째 줄의 0번 인덱스에 위치하므로 B텐서의 첫번째 줄에 0을 입력한 것이다.
12값이 첫번째 줄의 2번 인덱스에 위치하므로 B텐서의 첫번째 줄 두번째 요소에 2를 입력한다.
14값은 A텐서 두번째 줄에 1번 인덱스에 존재하므로 B텐서에 두번째 줄에 1을 입력한다.
13값은 A텐서 두번째 줄에 0번 인덱스에 존재하므로 B텐서 두번째 줄의 두번째 요소에 0을 입력한다.
17값은 A텐서 세번째 줄에 1번 인덱스에 존재하므로 B텐서 세번째 줄에 1을 입력한다.
18값은 A텐서 세번째 줄에 2번 인덱스에 존재하므로 B텐서 세번째 줄의 두번째 요소에 2를 입력한다.
C = A.gather(1, B)
gather 함수 첫번째 매개변수는 A텐서의 차원 중 몇차원의 값을 추출할 것인지를 지정하는 것이다.
여기서는 A텐서가 2차원인 상황이며, gather 첫번째 매개변수가 1이므로 A텐서 2차원 원소들 추출할 것을 지정하는 것이다.
gather함수는 실행결과로 B텐서에 기록된 위치정보를 이용해 A텐서에서 해당 위치의 원소 값들을 모아서 새로운 텐서로 리턴하게 된다.
결과 텐서 C는
C =>[[10, 12],[14, 13],[17, 18]]
epsilon-greedy 정책에 의해 선택되어진 액션정보를 담고 있는 행렬 a (32 * 1) 를 gather함수의 두번째 인자로 전달한다.



'인공지능 > 바닥부터 배우는 강화학습' 카테고리의 다른 글
| CH10. 알파고와 MCTS (0) | 2021.07.06 |
|---|---|
| ch09. 정책기반 에이전트 (0) | 2021.06.29 |
| ch07. Deep RL 첫걸음 (0) | 2021.06.16 |
| ch06. MDP를 모를 때 최고의 정책 찾기 (0) | 2021.06.15 |
| ch05. MDP를 모를 때 밸류 평가하기 (0) | 2021.06.04 |