1. 아나콘다 설치
링크주소 (2020.02.27 기준) : https://www.anaconda.com/distribution/#download-section
Anaconda Python/R Distribution - Free Download
Anaconda Distribution is the world's most popular Python data science platform. Download the free version to access over 1500 data science packages and manage libraries and dependencies with Conda.
www.anaconda.com

(1) python 3.7 version - 64bit 설치
(2) 설치도중 나오는 아래 화면에서 첫번째 체크박스 선택

(3) 설치완료 후 정상설치 확인

아나콘다 프롬프트 관리자모드로 실행
python --version 입력하여 설치된 파이썬 버전확인되면 정상설치

pip list 입력하여 아나콘다를 통해 설치된 라이브러리 리스트 확인가능

2. tensorflow 설치 (아나콘다는 텐서플로우는 자동설치 안됨)

pip install tensorflow 명령을 사용하면 tensorflow 2.1이 설치되지만 실제 사용하기 위해 소스코드에서
import tensorflow 를 하게되면 아래와 같은 에러발생
"ImportError: DLL load failed: 지정된 모듈을 찾을 수 없습니다"
이런 이유때문에 pip install tensorflow==2.0 명령으로 tensorflow 2.0 버전 설치 (왜 에러가 나지 않는지 이유는 파악 안되었음)
3. Visual Studio Code 설치
링크주소(2020.02.27 기준) : https://code.visualstudio.com/download
Download Visual Studio Code - Mac, Linux, Windows
Visual Studio Code is free and available on your favorite platform - Linux, macOS, and Windows. Download Visual Studio Code to experience a redefined code editor, optimized for building and debugging modern web and cloud applications.
code.visualstudio.com

User Installer 64bit (현재 윈도우 계정 사용자만 사용)또는 System Installer 64bit(모든 사용자 사용) 다운받아 설치
4. 설치완료 후 vscode 실행
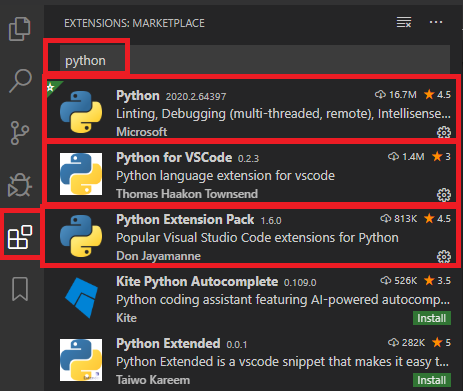
위 그림처럼 python , python for vscode, python extension pack 설치

위 그림처럼 Code Runner 설치