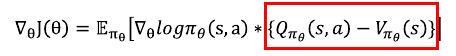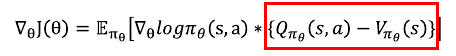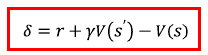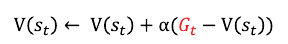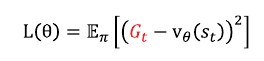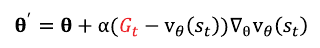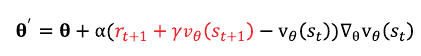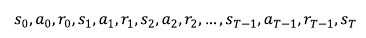* [바닥부터 배우는 강화학습] 도서를 읽고 정리한 글입니다
11.1 블레이드 & 소울 비무
B&S에는 PvP 즉, 유저들끼리 겨룰 수 있는 비무라는 컨텐츠가 있다.
링 안에서 상대와 일대일 무공 진검승부를 펼치는 컨텐츠이다.
3분의 제한시간 안에 상대방 체력을 0으로 만들면 이기며, 3분 안에 승부가 나지 않으면 상대방에게 가한 피해 합산이 높은 쪽이 이긴다.
공정한 경쟁을 위해 아이템 효과 사라지고 플레이어의 스탯( 캐릭터 강함의 지표)가 표준화된다.
1. 비무 속 도전과제
(1) 거대한 문제 공간
비무는 시점마다 선택해야 하는 액션의 종류만 3가지 이다.
\(a_{skill}, a_{move}, a_{target}\)
\(a_{skill}\)는 학습한 역사(Destroyer)라는 직업 기준으로 총 44가지 선택지가 있으며 순간마다 처해있는 상태에 따라 사용 가능 스킬이 바뀐다. 평균적으로 10개 정도 선택지가 사용 가능하다.
\(a_{move}\)는 동서남북 + 움직이지 않는 옵션 => 5가지 가능
\(a_{target}\)는 상대방을 바라보거나 진행방향을 바라보는 옵션 2가지를 제공한다.
조합 수를 계산하면 10*5*2 = 100 가지 종류의 액션 선택이 가능하다.
0.1초마다 1번의 결정을 해야 하며 평균게임길이가 90초이므로 900번의 액션을 실행한다.
따라서 경우의 수는 \(100^{900}\)이다.
바둑보다 훨씬 문제공간이 크다는 것을 알 수 있다.
(2) 실시간 게임이 갖는 제약
0.1초 안에 현재 상태 데이터 받고, 정책 네트워크가 액션을 선택하고, 그 액션을 다시 환경에 보내야 한다.
그리고 상대방의 액션을 미리 예측하는 과정도 필요하다.
짧은 시간 안에 처리해야 하므로 처리속도도 중요한 이슈가 된다.
(3) 물고 물리는 스킬관계
1. 상태이상(cc기) : 상대를 상태 이상에 빠뜨리는 스킬
2. 저항: 상대방의 cc기나 데미지 딜링기에 잠시 동안 면역상태 제공
3. 탈출: 상대의 cc기에 맞았다면 탈출기를 이용해 상태 이상을 벗어날 수 있다.
4. 데미지 딜링 : 상대 체력을 빼는 데에 특화된 기술
5. 이동: 단숨에 상대에게 접근하거나 거리를 벌리는 스킬
6. No-op : 아무 액션을 취하지 않음
스킬군에 따라 가위 바위 보 관계 형성하게 된다.
- No-op < 상태 이상기
- 상태 이상기 < 저항기
- 저항기 < No-op
이는 비무에 존재하는 무수히 많은 가위바위보 관계 중 하나일 뿐이며, 비무는 일정 시간내에 계속 이어지는 가위바위보 게임이라고 볼 수도 있다.
(4) 상대방에 관계없이 robust 한 성능
상대방이 누구든 어떤 성향을 가지든 좋은 결과를 가져오도록 해야 한다.
이를 위해 새로운 self-play 커리큘럼을 도입했다.
11.2 비무에 강화 학습 적용하기

1. MDP만들기
MDP형태로 만들기 위해 우선 이산적인 시간 단위로 쪼갠다.
논문에서는 0.1초를 1틱으로 정했다.
이보다 빠르면 연산 속도가 부족하고 느리면 전체 반응속도가 느리게 된다.
에이전트는 0.1초마다 상태를 인풋으로 받아 액션을 결정하여 환경(게임엔진)에 보낸다.
그에 따라 환경(게임엔진)은 상태 변화를 일으키고 다음 상태를 에이전트에게 전달한다.
(1) 관측치(\(O_t\))
에이전트는 틱마다 환경 안에서 현재 게임 상황에 대한 다양한 정보\(O_t\)를 관측한다.
정확하게 보면 \(O_t\)와 \(S_t\)는 차이가 있다.
\(O_t, O_{t-1}, O_{t-2}, ... O_1\)를 묶어서 상태 \(S_t\)를 정의한다.
보다 "마르코프하게" 상태를 정의하기 위함이다.
\(O_t, O_{t-1}, O_{t-2}, ... O_1\)를 묶어서 상태 \(S_t\)를 정의하는 방법은 RNN 구조의 뉴럴 네트워크를 이용하면 된다. 논문에서는 RNN의 대표적 구조인 LSTM 구조를 사용했다.
LSTM을 이용하면 틱마다 관측치 \(O_t\)를 받아 그 중에 필요한 정보는 다음 틱으로 흘려보내고, 필요하지 않은 정보는 막는 방식으로 업데이트 된다. 그렇게 흘러간 정보와 해당 틱에서의 관측치 \(O_t\)를 바탕으로 뉴럴넷이 상태 \(S_t\)를 만든다.
\(O_t\)에는 플레이어가 관측할 수 있는 모든 정보를 그대로 에이전트에게 제공했다고 보면 된다.
(2) 액션(\(a_t\))
실제 액션공간은 너무나 크며, 모든 액션이 반드시 필요하진 않다.
액션을 \(a_{skill}\)과 \(a_{move,target}\) 2가지 종류로 줄인다.
\(a_{skill}\)에는 44개의 스킬에 더하여 아무 스킬도 사용하지 않는 "no-op"선택지를 하나 추가하여 총 45개 중 하나를 선택하도록 한다.
no-op를 추가한 이유는 스킬을 아껴야 하기 때문이며 사람도 경기 도중 액션의 80% 이상이 no-op일 정도록 중요한 액션이다.
\(a_{move,target}\)은 앞,뒤,좌,우 이동선택지와 no-move , 상대방과 반대쪽을 바라보고 움직이는 액션 총 6가지 제공한다.
에이전트는 \(a_{skill}\)과 \(a_{move,target}\) 두 종류 액션을 각각 하나씩 선택해서 환경인 게임엔진에 보내고 게임엔진은 그에 맞게 처리하고 상태변화를 일으킨다.
(3) 보상(\(r_t\))
보상 중 가장 먼저 생각할 수 있는 것은 승리여부이다.
하지만 이 보상은 한 게임에 한번 발생하는 희귀한 시그널이다.
최대 1800틱까지 길어지는 에피소드에서 한 번 존재하는 시그널을 이용해 강화하는 것은 어려운 일이다.
따라서 승패 보상을 기본으로 하되, 자주 발생하는 시그널을 더해줘야 한다.
다음과 같이 체력 차이를 이용해 보상을 준다

\(HP_t^{ag}\)는 t시점에 에이전트의 체력이고 \(HP_t^{op}\)는 t 시점에 적의 체력이다.
내 체력이 줄어들면 음의 보상을 받고, 적의 체력이 줄어들면 양의 보상을 받는다.
체력에 대한 보상은 자주 발생한다.
한 번 고려해야 하는 것은 체력에 대한 보상이 안전한 보상인가 하는 점이다.
예를 들어 살펴보자.
성향이 다른 게임 플레이어 A와 B가 있다.
A는 이길 때마다 체력을 조금 남기고 겨우 이기지만 승률이 100%이다.
B는 승률은 85%이지만 이길 때는 자신의 체력이 하나도 안 깍이고 완벽하게 상대를 압도한다.
누가 더 잘 하는 플레이어인가? 일반적으로 A이다.
하지만 체력을 보상으로 준다면 B가 A보다 보상을 더 많이 받을 수도 있다.
따라서 보상의 합을 최대화하는 것과 잘 플레이하는 것 사이에 약간의 미스매치가 발생하게 된다.
본 논문에서는 미스매치 감수하더라도 자주 발생하는 체력 보상을 이용해 학습하는 것이 더 이득이 된다.
Optimality(최적성)과 Frequency(빈도) 사이 트레이드 오프가 있다는 것이다.
제일 정확한 승패 시그널은 최적이지만 발생빈도가 너무 낮고, 자주 등장하는 체력 시그널은 최적은 아니지만 빈도가 높아 학습을 빠르게 한다.
논문에서는 승패보상과 체력보상 이 2가지를 메인으로 사용했다.

(4) 학습 시스템과 알고리즘
MDP의 기본요소에 대한 정의를 마쳤다.
다음은 학습과정에 대해 살펴본다.

학습시스템은 워커(worker)와 러너(learner)로 구성한다.
워커에서 하는 일은 다음과 같다.
각 워커는 중앙 모델DB에서 학습의 대상으로 최신 모델을 뽑고 대전 상대로는 과정 모델 중 하나를 랜덤하게 선택하여 경기를 진행한다. 경기가 끝나면 로그 파일을 중앙 리플레이 버퍼(CH08에서 DQN의 리플레이 버퍼)에 업로드 한다.
대략 100개의 워커가 1주일 동안 동시에 돌아갔으며 대략 2년에 해당하는 플레이 데이터를 확보했다.
(프로게이머와 대전을 위해서는 2주일간 학습했다)
러너는 정책 네트워크를 업데이트하는 역할을 한다.
리플레이 버퍼에서 로그를 가져와 정책 네트워크를 업데이트하며 정해진 주기마다 정책 네트워크의 복사본을 모델DB에 업로드한다.
정책 네트워크 업데이트에 사용된 알고리즘은 ACER(Actor-Critic with Experience Replay)를 사용했다.
해당 알고리즘은 A3C(Asynchronuous Advantage Actor-Critic)의 off-policy 버전 알고리즘이라고 보면 된다.
A3C는 CH09에서 언급했던 액터-크리틱 알고리즘을 여러 쓰레드를 이용해 병렬적으로 업데이트 할 수 있도록 수정한 알고리즘이다.
각각의 액터(혹은 워커)가 비동기적으로 작동하며 그라디언트를 계산하여 중앙에 보내며, 중앙에서는 그라디언트가 올 때마다 모델을 업데이트하여 다시 각각의 액터에 보내주는 방식이다.
A3C는 기본적으로 on-policy 알고리즘이다. 즉 경험을 쌓는 네트워크와 학습을 받고 있는 네트워크가 동일해야 한다는 의미이다.
ACER는 A3C에 importance sampling 기법을 사용하여 경험하는 네트워크가 계산한 그라디언트를 학습하는 네트워크 관점에서 수정하여 올바른 그라디언트를 계산하도록 해준다.
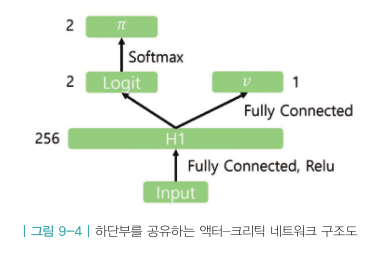
학습대상 네트워크는 크게 2개의 정책 네트워크와 2개의 액션-밸류 네트워크 총 4가지이다.
- 스킬을 결정하는 네트워크 \(\pi_{skill}\),
- 이동과 타깃팅을 결정하는 네트워크 \(\pi_{move,target}\),
- 스킬 액션의 가치를 평가하는 네트워크 \(Q_{skill}\),
- 이동과 타깃의 가치를 평가하는 네트워크 \(Q_{move,target}\)
그리고 위 4개의 네트워크가 모두 하단부를 공유한다.
특정 시점의 관측치 \(o_t\)가 들어오면 몇 개의 히든 레이어를 거쳐 LSTM에 들어간다.
그리고 LSTM에서 나온 아웃풋(상태 \(s_t\))이 4개의 네트워크 공통 인풋으로 들어가 4개의 네트워크의 아웃풋으로 나온다.
정책 네트워크가 2개라는 점을 생각해보자.
\(\pi_{skill}\)과 \(\pi_{move,target}\) 2개의 네트워크를 학습해야 한다.
여러 개의 정책 네트워크를 학습하는 방법은 3가지가 있다.
첫번째, 번갈아가며 업데이트하는 방식이다.
두번째, 두 개의 정책 네트워크가 서로 독립이라고 가정하고 아래 계산식을 적용하는 방법

세번째, 두 종류의 액션 중 하나를 먼저 선택하고 다음에 다른 하나를 선택하는 방식이다.
스킬 액션을 먼저 선택한다면 스킬정책네트워크 \(\pi_{skill}\)을 먼저 실행해서 \(a_{skill}\)를 뽑고 \(a_{skill}\)을 인풋으로 \(a_{move,target}\)을 결정한다.
수식으로 표현하면 아래와 같다.

실제 신경망으로 구현할 때는 신경망 인풋으로 상태 정보와 선택된 액션 \(a_{skill}\)을 함께 제공한다.
논문에서는 간단한 방식인 첫 번째 방식을 선택했다.
(5) 이동 정책 네트워크의 학습
이동 액션은 0.1초 동안 움직임이 적기 때문에 상태 변화에 미치는 영향이 미미하며 그로 인해 학습에 어려움을 겪게 된다.
이 문제를 해결하기 위해 아래와 같은 방법을 적용했다.
이동 액션 10개를 묶어서 하나의 액션으로 생각하는 것이다.
이동 액션을 적용할 때 이동 방향이 정해지면 해당 방향으로 동일 액션을 10번 실행하는 것이다.
이동 학습을 하는데 사용할 수 있는 데이터 양은 줄지만 단일 액션의 효과를 키움으로 학습의 질을 올린다.
(6) 학습 결과
과거의 모델에 대해 승률이 고르게 향상되는 것이 이상적이며 특정 모델에 대한 승률이 적을 경우 해당 모델을 뽑을 비율을 높여서 다른 모델에 비해 더 많이 뽑힐 수 있도록 한다. 상대적으로 승률이 좋은 모델에 대해서는 뽑을 확률을 줄이도록 한다.
11.3 전투 스타일 유도를 통한 새로운 방식의 self-play학습
다양한 스타일의 상대방을 만나 학습을 해야 승률을 높일 수 있다.
1. 보상을 통한 전투 스타일 유도
격투 게임에서 스타일을 가르는 주요 요소는 공격성이다.
공격성을 조절하여 3가지 유형의 에이전트를 만들었다.
공격형, 수비형, 밸런스형 에이전트이다.
공격성을 조절해서 이 3가지 유형의 에이전트를 만들기 위해 보상 조절 방법을 사용했다.
보상은 크게 메인보상과 전투 스타일 보상 2가지로 나눠서 적용했다.
메인보상은 승패보상과 체결에 관한 보상이다. 플레이를 잘 하도록 하기 위해 메인보상을 최대화하도록 학습한다.
추가적으로 전투 스타일 보상은 3가지 측면에서 보상을 조절했다.

첫번째는 체력 측면에서 보상조절이다.
공격적인 에이전트는 자신의 체력을 내주더라도 상대의 체력을 깍는 것이 중요하다. 따라서 상대방 체력 비율을 더 높게 책정한다.
수비적인 에이전트는 상대 체력을 덜 깍더라도 자신의 체력을 보존하는 것이 더 중요하다. 따라서 자신의 체력 비율을 더 높게 책정하는 것이다.
두 번째는 경기 시간에 대한 패널티이다.
공격적 에이전트는 틱마다 상대적으로 커다란 음의 보상을 받는다. 따라서 최대한 빠른 시간안에 종료시키는 것이 유리하다. 이를 위해 상대방에게 계속적으로 공격을 시도하게 될 것이다.
수비적 에이전트는 시간 패널티를 주지 않는다.
세번째는 거리에 대한 패널티이다.
공격적 에이전트는 상대방과의 거리에 비례해서 패널티를 준다.
수비적 에이전트는 거리에 대한 패널티를 주지 않아 상대방에게 다가갈 유인이 없도록 한다.
2. 새로운 self-play 커리큘럼

3가지 스타일의 3개의 러너가 존재하며 각각의 러너는 해당하는 스타일의 고유한 보상을 통해 에이전트를 학습시킨다.
3개의 러너는 각각 사용하는 보상함수만 다를 뿐 학습 알고리즘이나 업데이트 방식은 모두 동일하다.
이와 같이 self-play 도중 상대방의 다양화를 꾀하는 방법론은 강화학습의 성능을 높이기 위해 많이 사용하는 방법론이다.
'인공지능 > 바닥부터 배우는 강화학습' 카테고리의 다른 글
| CH10. 알파고와 MCTS (0) | 2021.07.06 |
|---|---|
| ch09. 정책기반 에이전트 (0) | 2021.06.29 |
| ch08. 가치기반 에이전트 (0) | 2021.06.22 |
| ch07. Deep RL 첫걸음 (0) | 2021.06.16 |
| ch06. MDP를 모를 때 최고의 정책 찾기 (0) | 2021.06.15 |