* [바닥부터 배우는 강화학습] 도서를 읽고 정리한 글입니다
1. 벨만 방정식 소개
주어진 상태의 밸류를 구하는 실제 방법에 벨만 방정식이 사용된다.
벨만 방정식은 시점 t 에서의 밸류와 시점 t+1 에서의 밸류 사이의 관계를 다루고 있으며
또 가치함수와 정책함수 사이의 관계도 다루고 있다.
벨만 방정식은 현재 시점 (t)와 다음 시점(t+1) 사이의 재귀적 관계를 이용해 정의된다.
벨만 방정식은 벨만 기대 방정식과 벨만 최적 방정식이 있다.
2. 벨만 기대 방정식
벨만 기대 방정식을 아래와 같이 편의상 세 단계로 나눠 볼 수 있다.

(1) 0단계
\( \nu_{\pi}(S_t) = \mathbb{E}_{\pi} \left [ r_{t+1} + \gamma \nu_{\pi}(S_{t+1}) \right ] \) 증명 및 의미

위 풀이식을 해석을 해보면,
상태 \( s_t \)의 가치밸류는 상태 \( s_t \)에서 부터 미래에 받을 보상을 더해준 리턴의 기댓값인데, 풀어서 생각해보면 한 스텝 더 진행하여 보상을 받고, 그 다음 상태인 \( s_{t+1} \) 부터 미래에 받을 보상(리턴)을 더해줘도 같은 결과를 가져온다는 것이다.
더 연장해서 생각해보면 \( s_{t+1} \) 상태로 진행한 후 한스탭 더 진행해서 보상을 받고 그 다음상태인 \( s_{t+2} \) 부터 미래에 받을 보상(리턴)을 더해줘도 같은 결과를 가져온다
이것을 수식으로 표현해보면 아래와 같다.
$$ \nu_{\pi} (s_t) = \mathbb{E}_{\pi} \left [ r_{t+1} + \gamma r_{t+2} + \gamma^2 \nu_{\pi} (s_{t+2}) \right ] $$
같은 원리로 액션가치함수에 대해서도 적용할 수 있다.
$$ \mathbf{q}_{\pi}(s_t, a_t) = \mathbb{E}_{\pi} \left [ r_{t+1} + \gamma \mathbf{q}_{\pi}(s_{t+1}, a_{t+1}) \right ] $$
$$ \mathbf{q}_{\pi}(s_t, a_t) = \mathbb{E}_{\pi} \left [ r_{t+1} + \gamma r_{t+2} + \gamma^2 \mathbf{q}_{\pi}(s_{t+2}, a_{t+2}) \right ] $$
풀이식에서 하나 더 주목해야 할 부분은 기댓값에 대한 부분이다.
\( s_t \)에서 시작하여 \( s_{t+1} \)이 정해지기까지 두 번의 확률적인 과정을 거쳐야 한다.
쉽게 이야기하면 두번의 동전던지기 과정이 필요하다.

첫번째는 상태 \( s_t \)에서 액션 \( a_t \)를 선택하는 과정에서 필요하다
이때는 정책확률분포 ( \( \pi \) 에 따라 액션이 정해진다.
예를 들어 수식으로 표현하면,
$$ \pi (a_1 \vert s_t) = 0.6, \pi (a_2 \vert s_t ) = 0.4 $$
이 수식을 해석하면 상태 \( s_t \)에서 액션을 정할 때 \( a_1 (앞면) \)을 선택하게 될 확률 0.6, \( a_2 (뒷면) \)를 선택하게 될 확률 0.4 를 가지는 정책이라는 의미이다. 그리고 이 정책 확률분포에 따라 동전던지기를 실행한다는 것이다.
이 부분을 위 그림에서는 \( \pi \)의 동전던지기 라고 표현했다.
이 과정을 거쳐 액션이 선택되면 그 다음 과정은 환경이 전이확률에 따라 (동전을 던져) 다음 상태 \( s_{t+1} \) 를 정하게 된다.
상태 전이하는 과정에서 이렇게 확률분포에 따라 선택되어 지는 과정(동전던지기)를 수행해야 하기 때문에 매번 결과가 같게 나올 수 없으므로 이 부분을 수식으로 표현하기 위해 기댓값이 사용된 것이다.
(2) 1단계
벨만 방정식 1단계에는 액션 밸류 \( \mathbf{q}_{\pi}(s, a) \) 를 이용해 상태 밸류 \( \nu_{\pi}(s) \) 를 표현하는 식과 \( \nu_{\pi} (s) \)를 이용하여 \( \mathbf{q}_{\pi}(s, a) \)를 표현하는 식으로 구성되어 있다.
왜 1단계에서 이 둘의 관계를 정리하는 방정식이 등장했을까?
0단계에서 언급한 것처럼 상태 전이 과정에는 액션의 선택과정과 그것을 토대로 다음상태를 선택하는 2가지 과정이 내포되어 있다.
즉, 다음상태로 전이과정이 둘과의 관계가 정리되어야 전이과정의 풀이를 한쪽만의 공식으로 나타낼 수 있게 될 것이다.
1) \( \mathbf{q}_{\pi} \)를 이용해 \( \nu_{\pi} \)를 계산하기

다음은 위 식을 예를 들어 설명한다.

정책은 그림의 확률분포를 따른다고 가정하며, \( a_1 \) 선택시 액션밸류(액션가치)는 1, \( a_2 \)를 선택시 액션밸류(액션가치)는 2를 가지고 있다고 가정할 때 상태s 의 밸류 계산식은 다음과 같다.

2) \( \nu_{\pi} \)를 이용해 \( \mathbf{q}_{\pi} \) 계산하기

다음은 위 식을 예를 들어 설명한다.

위 식을 이용해 상태s 에서 액션 \( a_1 \) 선택시 밸류를 구하는 위해서는 아래의 전제조건이 필요하다.
a) \(a_1 \)선택시 받는 보상을 알아야 한다 (그림에서는 0.5)
b) 상태 s에서 액션 \(a_1 \) 선택시 다음 상태로의 전이확률 \( P_{ss^{'}}^a \) 을 알아야 한다.
(그림에서는 \(s_1 \)으로 이동확률은 70%, \(s_2 \)로 이동확률은 30%이다)
c) 다음상태로 전이된 후 각 상태의 밸류를 알아야 한다.
(그림에서는 \(s_1 \)의 상태밸류\( \nu_{\pi}(s_1) \)는 1.5 , \(s_2 \)의 상태밸류\( \nu_{\pi}(s_2) \)는 -1 이다)

(3) 2단계
1단계의 \( \mathbf{q}_{\pi} \)에 대한 식을 \( \nu_{\pi} \)에 대한 식에 대입하면 아래와 같은 결과 식이 나온다.

반대로 \( \nu_{\pi} \)에 대한 식을 \( \mathbf{q}_{\pi} \)에 대한 식에 대입하면 다음과 같은 결과식을 얻는다.

2단계의 공식은 0단계 공식의 실제 계산에 사용되는 공식이라고 보며 된다.
0단계와 2단계 수식을 같이 적어보면 아래와 같다.

0단계에서 기댓값 실제 계산을 2단계 공식을 사용한다고 보면 된다.
단, 이때 전제조건은 아래 2가지를 알고 있어야 한다.
- 보상함수 \( r_{s}^{a} \) : 각 상태에서 액션을 선택하면 얻는 보상
- 전이확률 \( P_{ss^{'}}^{a} \) : 각 상태에서 액션을 선택하면 다음 상태가 어디가 될지에 관한 확률분포
이 2가지는 환경의 일부이며 이 2가지에 대한 정보를 알 때 "MDP를 안다"고 표현한다.
하지만 실제 환경에서는 이 2가지를 모르는 경우도 많다.
즉, MDP에 대한 정보를 모르는 상태에서 학습하는 접근법을 "모델-프리" 접근법이라 한다.
반대로 이 2가지에 대한 정보를 알고 있는 경우 학습하는 접근법을 "모델 기반" 혹은 "플래닝" 접근법 이라고 한다.
MDP 모든 정보를 알 때는 벨만 기대 방정식 중 2단계 식을 이용하며,
MDP 정보를 모를 때에는 0단계 식을 이용한다.
2. 벨만 최적 방정식
(1) 최적밸류와 최적 정책

어떤 MDP가 주어졌을 때 그 MDP안에 존재하는 모든 \( \pi \)들 중에서 가장 좋은 \( \pi \)를( 즉 \( \nu_{\pi}(s) \) 의 값을 가장 높게 하는 정책) 선택하여 계산한 밸류가 최적 밸류 \( \nu_{*}(s) \)라는 뜻이다.
\( \mathbf{q}_{*}(s,a) \)도 마찬가지 의미이다.
만일 상태별로 가장 높은 밸류를 주는 정책이 다르면, 예컨대 \( s_0 \)의 밸류는 \( \pi_{238} \)를 따를 때 최고이고 \( s_1 \)의 밸류는 \( \pi_{345} \) 를 따를 때 최고인 경우, 이런 경우는 각 상태별로 최고인 정책을 따르는 새로운 정책\( \pi_{*} \)를 생각할 수 있다.
해당 정책을 따르면 모든 상태에 대해 그 어떤 정책보다 높은 밸류를 얻게 되는 이러한 정책을 최적 정책 이라고 한다.
(2) 벨만 최적 방정식

1) 0단계 수식 설명
이 식은 밸만 기대 방정식 0단계 수식의 취지와 같은 취지의 수식이다.
"상태s에서 최적 밸류는 한 스탭만큼 진행해서 보상을 받고, 다음 상태인 \( s^{'} \)의 최적 밸류를 더해줘도 같다" 는 의미이다.
여기서 기댓값이 들어가 있는 이유는 액션a에서 다음상태로 전이될 때 사용되는 전이확률는 계속 사용되기 때문에 매번 전이된 상태가 다르며 그로 인해 기댓값이 사용되었다.
2) 1단계 수식 설명
a) \( \mathbf{q}_{*} \)를 이용해 \( \nu_{*} \) 계산하기
$$ \nu_{*}(s) = \underset{a}{\max} \mathbf{q}_{*} (s,a) $$
위 수식의 의미는 다음과 같다.
"상태 s의 최적밸류는 s 상태에서 선택할 수 있는 모든 액션들 중에 가장 높은 액션밸류와 같다."
아래 그림과 같은 상황으로 위 식을 좀 더 설명한다

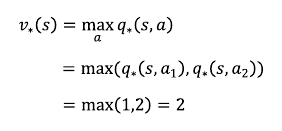
벨만 기대 방정식 1단계에서
$$ \nu_{\pi}(s) = \sum_{a \in A} \pi(a \vert s) \mathbf{q}_{\pi}(s, a) $$
\( \pi(a \vert s) \) 부분이 빠진 이유는 상태 s에서 액션 a를 선택하는 방법은 정책확률에 따라 선택했었으나
벨만 최적 방정식에서는 액션밸류가 최대가 되는 a를 선택하는 방식이기 때문에 확률적 접근을 하지 않게 된다. 따라서 확률정보를 가지고 있는 정책확률 \( \pi \)가 필요없게 되어 빠진 것이다.
b) \( \nu_{*} \)를 이용해 \( \mathbf{q}_{*} \)계산하기
$$ \mathbf{q}_{*}(s, a) = r_{s}^{a} +\gamma \sum_{s^{'} \in S} P_{ss^{'}}^{a} \nu_{*}(s^{'}) $$
이 식은 벨만 기대방정식 1단계 \( \mathbf{q}_{\pi}(s, a) \)와 거의 같다. \( \pi \)가 * 로 변경되었다고 보면 된다.
이 식의 의미는 다음과 같다.
상태 s에서 액션a 의 액션밸류의 최대값은 그 상태에서 a액션 선택했을 때 받는 보상과 , 전이확률에 의해 다음 상태로 이동했을 때 이동한 상태에서의 최적의 상태밸류들의 합산 값을 감마 만큼 감쇠한 값을 합산한 것이다.
3) 2단계 수식 설명
1단계 수식 2개를 조합하여 2단계 수식을 구성할 수 있다.

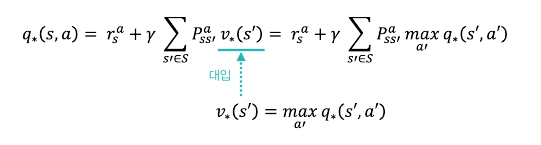
2단계 수식을 사용하여 최적밸류를 계산하기 위해서는 기대방정식에서와 같이 보상과 전이확률을 알고 있어야 한다.
즉, MDP를 알고 있을 때 사용할 수 있는 수식이다.
정리차원에서 위에서 나온 벨만 기대 방정식과 최적 방정식을 같이 나열해본다.
1. 벨만 기대 방정식

2. 벨만 최적 방정식

벨만 방정식을 큰 틀에서 정리해보면,
MDP 상에서 정책 \( \pi \) 가 주어지고 해당 정책을 평가해야 하는 경우 벨만 기대방정식을 사용하여 계산한다.
최적의 밸류를 찾아야 할 경우는 벨만 최적방정식을 사용한다.
이후 과정에서 벨만 방정식에 대해 더 세부적으로 다룰 것이다.
'인공지능 > 바닥부터 배우는 강화학습' 카테고리의 다른 글
| ch05. MDP를 모를 때 밸류 평가하기 (0) | 2021.06.04 |
|---|---|
| ch 04. MDP를 알 때의 플래닝 (0) | 2021.06.02 |
| ch 2-4. 마르코프 결정 프로세스(Markov Decision Process) - Prediction과 Control (0) | 2021.05.26 |
| ch 2-3 마르코프 결정 프로세스(Markov Decision Process)-MDP (0) | 2021.05.25 |
| ch2-2. 마르코프 결정 프로세스(Markov Decision Process-MDP)-마르코프 리워드 프로세스 (0) | 2021.05.23 |