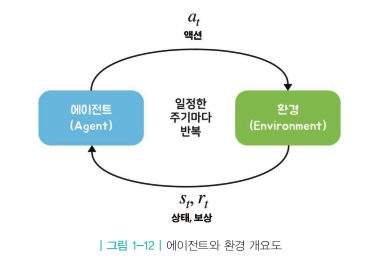
* 바닥부터 배우는 강화학습 도서를 읽고 정리한 글입니다
1. 마르코프 프로세스(Markov Process)
(1) 정의
미리 정의된 어떤 확률 분포를 따라서 정해진 시간 간격으로 상태와 상태 사이를 이동해 다니는 과정(Process)
=> 어떤 상태에 도착하면 다음상태가 어디가 될지 정의된 확률에 따라 정해지게 된다
하나의 상태에서 다음 상태로 이동을 가리키는 화살표는 확률에 따라 여러 개가 나타날 수 있으며 각 화살표로 이동확률의 합은 100% 이다
- 마르코프 프로세스 정의 표현식
$$ MP \equiv (S, P) $$
- 상태의 집합 S
마르코프 프로세스 전 과정에서 가능한 상태를 모두 모아놓은 집합 => S
- 전이확률 행렬 P
$$ P_{ss^{'}} $$
상태 \( S \) 에서 다음상태 \( S^{'} \) 로 이동할 확률을 의미한다
전이확률을 조건부 확률식으로 풀어서 표현하면 다음과 같다
$$ P_{ss^{'}} = \mathbb{P} \left [ S_{t+1} = s^{'} \vert S_t = s \right ] $$
전이확률행렬 이라고 표현하는 이유는 \( P_{ss^{'}} \) 값을 각 상태 \( s \) 와 \( s^{'} \)에 대해 행렬의 형태로 표현할 수 있기 때문이다.
만일 특정 마르코프 프로세스에서 모든 상태의 갯수가 5개라면 총 25개 확률값으로 구성된 전이확률 행렬을 구성할 수 있다.

위의 전이확률행렬을 이용하여 마르코프 프로세스를 그리면 아래와 같다

(2) 마르코프 성질
마르코프 성질은 다음과 같다
"미래는 오직 현재에 의해 결정된다"
$$ \mathbb{P} \left [ S_{t+1} \vert S_t \right ] = \mathbb{P} \left [ S_{t+1} \vert S_1 , S_2 , ... , S_t \right ] $$
마르코프한 성질의 프로세스 예시
예를 들면, 체스 게임 - 다음 둘 수를 판단할 때 현재 체스 판의 상태만 분석하면 다음 둘 수를 (다음 상태) 결정할 수 있다. 즉 체스 게임은 마르코프 성질을 따르는 프로세스라고 할 수 있다.
마르코프한 상태인지 판단하는 한 가지 방법은 과거이력 정보가 없는 현재상태만 캡쳐한 정보를 가지고 최선의 다음 상태를 고려할 수 있나, 아니면 과거이력정보를 알면 더 좋은 다음 상태 선택이 가능한 가를 질의해 보는 것이다.
만일 현재상태 정보만 가지고 최선의 다음상태 선택이 가능하다면 마르코프한 성질을 따르는 프로세스라고 할 수 있다.
- 마르코프한 성질을 가지지 않는 프로세스 예시
예를 들면, 운전 - 현재 자동자 주변 상황을 사진으로 찍어놓고 지금 상태에서 다음에 브레이크를 밟아야 할지 엑셀을 밟아야 할지 판단할 수 없다
따라서 단순히 이런 방식으로 고려한다면 운전은 마르코프 성질을 따르지 않는 프로세스 라고 할 수 있다.
하지만, 만일 1초 마다 자동자 주변상황을 찍어서 과거 사진 10장을 (즉 10초 전 상황) 하나의 상태로 묶어서 제공된다면 다음 상황을 고려할 수 있게 된다.
(영국 딥마인드사에서는 비디오 게임 학습시킬 때, 시점 t 에서의 이미지와 함께 t-1, t-2, t-3 의 과거 이미지를 엮어서 하나의 상태로 제공하였다. 이렇게 함으로 해당 프로세스를 조금이라도 더 마르코프 성질을 따르도록 하기 위함이다)
어떤 현상을 마르코프 프로세스로 모델링 하려면 상태가 마르코프 해야 하며, 단일 상태 정보만으로도 정보가 충분하도록 상태를 잘 구성해야 한다
'인공지능 > 바닥부터 배우는 강화학습' 카테고리의 다른 글
| ch 3. 벨만 방정식 (0) | 2021.05.29 |
|---|---|
| ch 2-4. 마르코프 결정 프로세스(Markov Decision Process) - Prediction과 Control (0) | 2021.05.26 |
| ch 2-3 마르코프 결정 프로세스(Markov Decision Process)-MDP (0) | 2021.05.25 |
| ch2-2. 마르코프 결정 프로세스(Markov Decision Process-MDP)-마르코프 리워드 프로세스 (0) | 2021.05.23 |
| ch 1. 강화학습이란 (0) | 2021.05.19 |