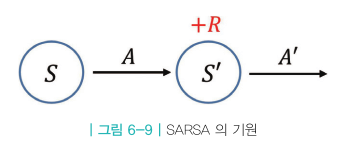
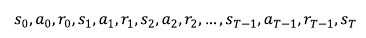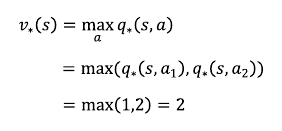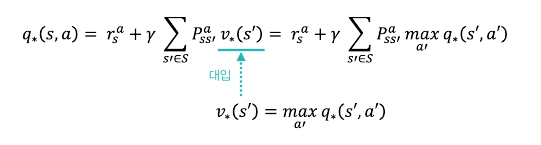* [바닥부터 배우는 강화학습] 도서를 읽고 정리한 글입니다
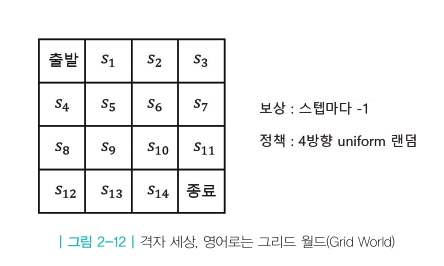
이제부터 상태가 무수히 많은 규모가 큰 MDP를 푸는 법에 대해 논의한다.
7.1 함수를 활용한 근사
상태가 많아지면 테이블의 사이즈가 기하급수적으로 커지므로 테이블 기반 방법론을 사용할 수 없게 된다.
새로운 접근법이 필요하다.
예를 들면, 상태값을 입력시켜 결과값으로 가치값을 리턴하는 함수를 구할 수 있다면,
상태값과 가치값을 저장하는 테이블 방식보다 함수 정보만 가지고 있으면 되므로 메모리 사용이나 시간상 많은 이점이 있을 것이다.
하지만, 정확하게 실제 가치값을 도출해 내는 함수를 구하기는 어려우므로 근사함수를 구해서 사용할 수 있다.
실제 값에 가장 가깝게 근사하도록 함수 파라미터를 구하는 법으로 주로 "최소 제곱법"을 사용합니다.

1. 함수 복잡도에 따른 차이
함수의 차수가 높을 수록 아래 그림과 같이 실제 결과값과 거의 일치하게 근사시킬 수 있다.
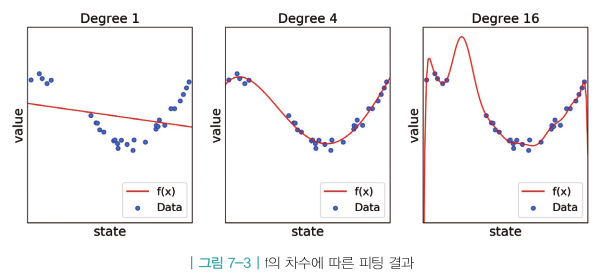
하지만 실제 데이터에는 노이즈가 섞여 있으므로 실제 데이터값에 정확하게 피팅하면 오히려 구하고자 하는 평균치 데이터(가치밸류)와는 멀어질 수도 있게 된다. 즉, 높은 차수의 다항함수를 사용하는 것이 무조건 정확하다고 볼 수는 없다.
2. 오버피팅과 언더피팅
오버피팅 : 근사함수를 정할 때 , 너무 유연한 함수를 사용하여 노이즈까지 피팅해 버리는 현상
언더피팅 : 실제 모델을 담기에 함수의 유연성이 부족하여 주어진 데이터와의 에러가 큰 상황

위 그림에서 빨간선은 근사함수이며 녹색선이 실제 모델 함수이다.
좌측그림은 언더피팅, 우측그림은 오버피팅을 나타낸다.
3. 함수의 장점 - 일반화
이미 경험한 데이터들을 바탕으로 실제 모델 함수에 근사한 함수를 잘 구성한다면 경험하지 않은 데이터를 근사함수에 입력하였을 때 실제 데이터와 오차가 적은 결과값을 리턴하게 될 것이다. 이런 함수의 특징을 일반화라고 한다.
이 특징때문에 잘 근사된 함수를 사용하게 되면 데이터를 저장하기 위한 공간을 대폭 줄일 수 있게 된다.
7.2 인공 신경망의 도입
1. 신경망
신경망의 본질은 매우 유연한 함수이다. 함수에 포함된 프리 파라미터의 개수를 통해 함수의 유연성을 제어한다.
(근래 커다란 신경망의 프리 파라미터가 1000억개를 넘어가기도 한다)
이러한 특징을 가지고 있는 신경망을 이용해서 상태별 가치값을 계산되도록 하려는 것이 Deep RL 학습의 중심 아이디어이다.
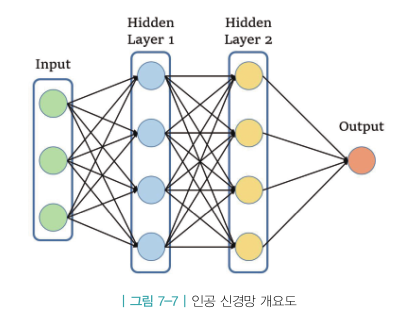
위 그림은 길이 3인 벡터를 인풋으로 받아 2층으로 쌓여있는 히든레이어를 통과시켜 결과값 하나를 도출해내는 신경망을 나타낸다.
함수로 표현하면 y = f(\(x_1, x_2, x_3\)) 형태이다.
히든레이어들은 노드로 구성되어 있으므로 신경망의 최소단위를 노드라고 할 수 있다. 따라서 노드를 이해하면 신경망 이해에 도움이 된다.

위그림은 하나의 노드만 떼어내어 표현한 것이다.
(1) 인풋 (\(x_1, x_2, x_3\))을 \(w_1x_1 + w_2x_2+w_3x_3 + b\)의 형태로 선형결합시킨다.
(2) g(x)라는 비선형 함수를 적용한다. (예를 들면, RELU함수 => g(x) = max(0, x))
여기서 선형결합의 의미는 인풋값들을 조합하여 새로운 피처(특징값)를 만드는 과정이다.
또한 비선형함수 적용은 인풋과 아웃풋의 관계가 비선형일 수 있기에 필요한 과정이다.
2. 신경망의 학습 - 그라디언트 디센트
제공된 데이터를 근거로 신경망 함수의 w 파라미터를 구하는 방법으로 그라디언트 디센트 방법을 사용한다.
실제 모델의 함수를 F(x)라 하고 근사함수를 f(x)라 하면 두 함수의 차이를 줄이는 것이 최종 신경망 학습의 목표이다.
이를 위해 아래와 같은 두 함수의 차의 제곱을 함수로 구성할 수 있다.
$$ L(w) = \{ F - f \}^2 $$
여기서 L(w)을 손실함수(loss function)라고 한다.
이 손실함수값을 최소화하는 것이 결국 신경망의 목표가 되는 것이다.
해당 신경망 모델에 100개의 w 파라미터가 존재한다고 가정할 때,
파라미터 별로 편미분을 통해 해당 파라미터 항이 함수 전체에 미치는 영향을 파악한다.

위 식은 함수의 각 파라미터에 대해 편미분하여 벡터를 만든 것이고, 이를 그라디언트 라고 한다.
계산된 그라디언트를 이용해 손실함수를 최소화 하는 방향으로 아래 수식처럼 파라미터를 조금씩 업데이트 해 나간다.

이런 과정을 그라디언트 디센트(경사하강법) 방법이라고 한다.
여기서 편미분결과를 반영하는 비율 \( \alpha \)를 러닝레이트 또는 스텝사이즈라고 한다.
보통 러닝레이트 값은 1보다 작은 값으로 셋팅합니다.
그라디언트 디센트 방법을 반복하면서 파라미터값을 업데이트 시켜가면 결국 손실함수가 최소가 되는 방향으로 파라미터들이 조정되는 것이고 결국 실제 데이터 모델에 근사한 함수를 구성할 수 있게 되는 것이다.
3. 간단한 확인
간단한 함수로 예를 들어 위의 과정을 살펴보겠다.
아래와 같은 근사 함수 \( f_w \)가 있다.

초기 w파라미터는 랜덤하게 셋팅한다.
\( w_1 = 0.5, w_2 = 1.2 \) 라고 하자.
그리고 학습을 위해 주어진 경험치 데이터는 \( (x_1, x_2, y) = (1, 2, 1) \) 이다.
즉,
$$ f_w(1,2) = 1 $$
만족하도록 w를 조정하는 것이 목표이다.
현재 상황에서 손실함수 L(w)는 아래와 같이 정의된다.

각 파라미터별로 편미분하면 아래와 같다.

구해진 그라디언트 벡터를 이용해 w 파라미터를 업데이트 한다(이때, 런닝레이트 \( \alpha \) = 0.01)
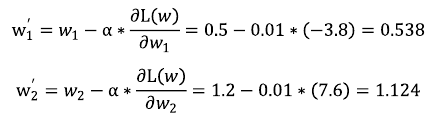
업데이트 된 w 파라미터를 이용해 \( f_w^{'}(1,2) \) 값을 계산했을 때 아래 결과에서 보듯이 w 파라미터 업데이트 전보다 실제결과값 1에 가까워졌다.

위 과정을 계속 반복하여 w파라미터를 업데이트함으로 실제 결과값에 점차로 가까워게 되며 결국 실제모델에 가까운 신경망함수를 얻게 되는 것이다. (이때 주의할 사항은 오버피트 이다)
4. 파이토치를 이용한 신경망 구현
간단한 실제 모델을 주고, 신경망 학습을 통해 근사함수를 구하는 과정을 파이토치를 활용해 구현해본다.
실제모델은 아래와 같다.

위 식에서 노이즈 U(-0.2, 0.2)는 -0.2에서 0.2 사이값을 실제값에 균등분포 시킨다는 것을 의미한다.
또한, 신경망의 모델은 아래와 같다.

인풋과 아웃풋은 각각 스칼라값 하나이고, 총 3개의 히든 레이어를 갖고 있으며 각 레이어에는 128개의 노드가 포함되어 있다. 또한 각 레이어에는 활성홤수 ReLU가 포함되어 있다.
이제부터, 위의 모델을 파이토치로 구현한다.


forward 함수에서 레이어별로 활성함수 ReLU 를 적용하고 있다.




'인공지능 > 바닥부터 배우는 강화학습' 카테고리의 다른 글
| ch09. 정책기반 에이전트 (0) | 2021.06.29 |
|---|---|
| ch08. 가치기반 에이전트 (0) | 2021.06.22 |
| ch06. MDP를 모를 때 최고의 정책 찾기 (0) | 2021.06.15 |
| ch05. MDP를 모를 때 밸류 평가하기 (0) | 2021.06.04 |
| ch 04. MDP를 알 때의 플래닝 (0) | 2021.06.02 |