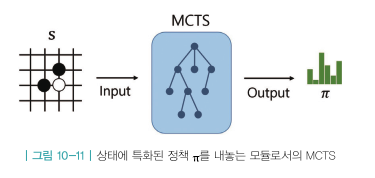
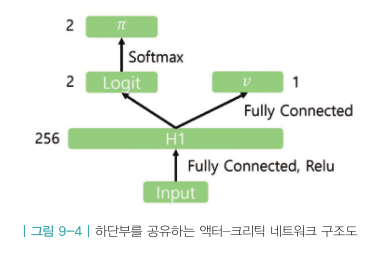
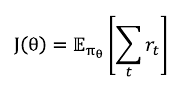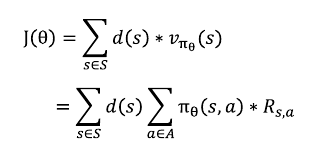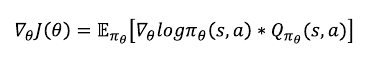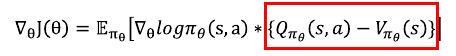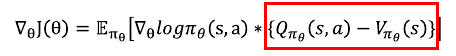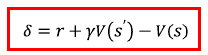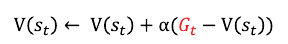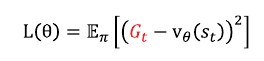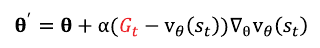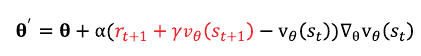CH09의 TD 액터-크리틱에서 사용했던 신경망과 유사하게 아랫단 레이어는 공유하며 윗단에서 갈라져 액션의 확률분포p와 밸류v를 리턴한다.
상태 \(s_t\)를 \(f_{\theta}\)에 인풋으로 넣어서 정책 네트워크 아웃풋 \(p_t\)와 밸류 네트워크 아웃풋 \(\nu_t\)를 계산한다.
정책 네트워크 아웃풋 \(p_t\)는 MCTS가 알려주는 확률분포 \(\pi_t\)와의 차이를 줄이는 방향으로 업데이트한다.
밸류 네트워크 아웃풋 \(\nu_t\)는 경기 결과값인 \(z_t\)와의 차이를 줄이는 방향으로 업데이트한다.
이를 근거로 손실함수를 구성하면 아래와 같다.
\(z_t\)와 \(\nu_t\) 사이는 MSE를 사용하여 손실함수를 구성하며, \(\pi_t\)와 \(p_t\) 사이는 크로스 엔트로피를 사용하여 손실함수를 구성한다.
위 식의 의미는 다음과 같이 풀어볼 수 있다.
MCTS가 알려준 액션 분포 \(\pi_t\)를 따라가도록 정책네트워크를 업데이트하고, MCTS를 이용해 진행한 게임결과(\(z_t\))를 예측하도록 밸류 네트워크를 업데이트 하는 것이다.
(2) 알파고 제로에서의 MCTS
알파고의 MCTS에서는 사전 준비물이 필요했다.
기보 데이터를 이용해 학습한 \(\pi_{sl}\)과 \(\pi_{roll}\), 그리고 강화 학습을 통해 얻은 \(\nu_{rl}\)이 더 이상 존재하지 않는다.
대신 아직 학습하지 않은 신경망 \(f_{\theta}(s) = (p,\nu)\) 가 있다.
이를 이용해 \(\pi_{sl}\) 대신 p를 사용하고 \(\nu_{rl}\) 대신 \(\nu\)를 사용한다.
\(\pi_{roll}\)는 사용하지 않는다.
확장단계와 시뮬레이션단계가 하나로 합쳐졌다.
확장단계에서 리프노드에서 뻗어나가는 액션의 사전확률은 \(\pi_{sl}\) 대신 \(f_{\theta}\)의 아웃풋인 p를 이용하여 초기화한다.
알파고의 MCTS에서는 시뮬레이션 단계에서 \(\pi_{roll}\)을 이용하여 얻은 시뮬레이션 결과와 밸류 함수 아웃풋 \(\nu\)의 평균을 사용했지만 , 알파고 제로에서는 리프노드 \(s_L\)의 밸류 평가시 \(f_{\theta}\)의 아웃풋인 \(\nu\)를 이용한다.
가치기반 에이전트는 결정론적이다. => 모든 상태s 에 대해 각 상태에서 선택하는 액션이 변하지 않는다는 의미이다.
학습이 종료된 후에는 해당 상태에서 Q(s,a)의 값이 가장 높은 액션을 선택하는 그리드 정책을 사용하게 되는데 학습이 종료된 상태에서는 q값이 고정되어 있기 때문에 각 상태에서 선택하는 액션이 변하지 않는 것이다.
이렇게 되면 가위바위보 게임을 한다고 할 때 특정상태에서는 계속 동일한 액션만 선택하게 되므로 상대에게 간파당하여 문제가 될 수 있다.
정책기반 에이전트는 확률적 정책을 취할 수 있다.
정책함수 정의가 아래와 같다.
$$ \pi(s,a) = P[a \vert s] $$
특정상태(s)에서 정책확률 분포에 따라 액션을 선택하게 되므로 유연한 정책을 가질 수 있다.
그리고 만일 액션 공간이 연속적인 경우, 예를 들면, 0에서 1사이 모든 실수값이 액션이 될 수 있는 상황이라면
액션이 무한하기 때문에 일일이 넣어볼 수 없어서 문제가 됩니다.
하지만 정책기반 에이전트는 \( \pi(s) \)가 주어져 있다면 정책함수 결과에 따라 액션을 계산해낼 수 있게 된다.
이번 챕터도 이전 챕터와 동일한 조건에서 뉴럴넷을 이용하여 표현한 정책 네트워크를 강화하는 것이 목적이다.
(1) 목적함수 정하기
정책 네트워크를 아래와 같이 표현한다.
$$ \pi_{\theta}(s,a) $$
여기서 \( \theta \)는 정책 네트워크의 파라미터이다.
파라미터를 미분하여 그라디언트 디센트 방식으로 업데이트 시키기 위해서는 손실함수를 정의해야 한다.
\( \pi_{\theta}(s,a) \)의 손실함수를 구하려면 먼저 정답지가 정의되어야 한다.
정책함수의 정답지를 알기 어려우므로 손실함수를 줄이는 방향이 아니라, 정책 평가 기준을 세워 그 값이 증가하도록 하는 방향으로 그라디언트 업데이트 시킨다.
정책평가함수를 \( J(\theta) \)라고 한다.
\( \theta \)를 입력으로 받아 \(\pi\) 정책을 실행하고 평가하여 점수를 리턴하는 함수이다.
해당 함수 값을 증가시키는 방향으로 그라디언트 어센트를 진행하여 강화학습을 하면 된다.
보상의 합이 큰 정책이 좋은 정책이라고 평가할 수 있다.
정책 \(\pi\)를 고정시켜도 에피소드 실행시마다 서로 다른 상태를 방문하고 다른 보상을 받는다.
따라서 정책평가시에도 기댓값 개념이 적용된다.
그러므로 정책평가를 아래와 같이 정의 내릴 수 있다.
위 식을 보면 한 에피소드의 모든 상태에서의 누적 보상합의 기댓값이 포함되어 있으며 이것이 결국 가치함수이다.
즉, \(s_0\)의 가치 라고 볼 수 있다.
여기서 시작 상태가 고정되어 있지 않은 일반적인 경우를 고려해보면 즉, 매번 다른 상태에서 출발한다고 보면
시작상태 s의 확률분포 d(s)가 정의되어 있을 때 아래 수식으로 정의를 표현할 수 있다.
이렇게 하면 \(\pi_{\theta}(s,a)\)를 평가할 수 있다.
따라서 \(\theta\)를 수정하여 \(J(\theta)\)를 최대화하는 그라디언트 어센트 방법을 적용하면 된다.
우선 \(J(\theta)\) 의 미분 계산 방법을 접근하기 쉬운 1-Step MDP 부터 살펴본다.
(2) 1-Step MDP
1-Step MDP는 한 스텝만 진행하고 바로 에피소드가 종료하는 MDP이다.
즉, 처음상태 \(s_0\)에서 액션 a를 선택하고 보상 \(R_{s,a}\)를 받고 종료하는 것이다.
또한 처음상태 \(s_0\)는 확률 d(s)를 통해 정해진다고 가정한다.
이런 경우 정책평가함수 \(J(\theta)\)는 다음과 같다.
이 정책평가함수를 미분하면 아래 유도과정을 거쳐 기댓값 연산자를 사용할 수 있게된다.
결국 아래와 같이 기댓값 연산자를 사용하여 표현할 수 있다.
미분과정을 기댓값 연산자를 사용할 수 있다는 것이 증명되었으므로 "샘플 기반 방법론"을 이용해 계산한다.
따라서 정책 \(\pi_{\theta}(s,a)\)로 움직이는 에이전트를 환경에 가져다 놓고, 에피소드를 반복적으로 수행시키면서
위 값을 모아 평균을 내면 된다.
\(\nabla_{\theta}log\pi_{\theta}(s,a)\)는 신경망 정책네트워크의 그라디언트를 통해 계산될 수 있으며,
\( R_{s,a}\)는 상태s에서 액션a를 선택하고 얻은 보상을 관측하면 된다.
위 공식의 유도과정을 통해 샘플기반 방법론으로 그라디언트 어센트 방법을 적용할 수 있다는 것이 증명됨으로 계산과정이 간단해진 것이다.
(3) 일반적인 MDP에서의 Policy Gradient
앞에서는 1Step-MDP에서의 Policy Grdient 계산법을 보았다. 일반적인 MDP로 확장하면 아래와 같이 식을 표현할 수 있다.
\(R_{s,a}\)가 \(Q_{\pi_{\theta}}(s,a)\)로 바뀌었다.
즉, 일반적 MDP에서는 하나의 에피소드가 여러스텝으로 구성되어 있으므로 해당 스텝에서의 보상만 고려하는 것이 아니라 해당 스텝에서의 누적보상합의 기댓값 (리턴의 기댓값)을 고려해야 하는 것이다.
위 식을 Policy Gradient Theorem 이라고 부른다.
정리하면, \(\pi_{\theta}(s,a)\) 정책을 따르는 에이전트가 반복적인 에피소드 경험을 통해 얻어낸 데이터를 기반으로 목적함수(정책평가함수) \(J(\theta)\)의 그라디언트를 계산하여 최적의 정책을 찾아내는 방법론을 policy gradient라고 한다.
9.2 REINFORCE 알고리즘
REINFORCE 알고리즘은 policy gradient를 이용해 실제로 학습하는 방법 중 가장 기초적이고 기본적인 알고리즘이다.
(1) 이론적 배경
원 수식의 \(Q_{\pi_{\theta}}(s,a)\) 자리에 특정 시점 t의 리턴값 \(G_t\)가 들어갔다.
Q 밸류 정의 식은 아래와 같다.
$$Q_{\pi}(s,a) = E[G_t \vert s_t = s, a_t = a]$$
즉, \(G_t\) 샘플을 여러 개 얻어 평균을 내면 그 값이 Q밸류가 되는 것이다.
이 정의를 고려해볼 때, 위 식의 바깥에 기댓값 연산자가 있기 때문에 괄호 안에 \(G_t\)를 적용해도 큰 차이가 없다는 논리이다.
2번의 A=>B=>C 반복은 더 이상 \(\theta\)의 변화가 없거나 성능의 향상이 없을 때까지 진행하면 된다.
(2) REINFORCE 구현
파이토치의 미분기능을 이용하려면 loss함수의 정의가 있어야 한다.
Policy Gradient 방법에서는 손실함수 대신 목적함수(정책평가함수) \(J(\theta)\)가 최대값을 가질 수 있도록 \(\theta\)를 업데이트 해야 한다.
따라서 구현상에서 필요한 것은 목적함수의 정의이다.
위에서 언급한 REINFORCE 알고리즘 수식은 다음과 같다.
여기서 미분 전의 공식은 미분기호를 제거한 아래의 수식이 된다.
실제로는 파이토치의 옵티마이저를 이용해 그라디언트 디센트 방법을 사용하여 결과적으로 그라디언트 어센트효과가 나오도록 해야 하므로 손실함수 위치에 들어갈 함수는 음의 부호를 추가하여 아래와 같다.
이 공식이 바로 손실함수 대신 정의하게 될 목적함수이다.
위 공식은 손실함수 위치에 대입될 공식이므로 이후 손실함수 또는 Loss라고 부르도록 한다.
이제부터 구현에 필요한 소스를 살펴본다.
Policy 클래스의 forward를 통해 나오는 결과 아웃풋은 좌측액션 확률과 우측액션 확률 값 2개를 리턴하게 된다.
2개의 확률정보를 근거로 m.sample에서 좌측이동 또는 우측이동 액션을 선택하게 된다.
확률이 큰쪽 액션이 무조건 선택되는 것이 아니다. 확률이 큰쪽의 액션이 뽑힐 확률이 더 높도록 한다는 것이 sample 함수 역할이다.
선택된 액션정보를 환경 env의 step함수에 입력하면 그 결과로 다음상태 정보와 보상, 종료여부 등의 정보를 리턴한다.
여기서 얻어진 보상과 Policy forward를 통해 얻은 확률정보를 에피소드 종료까지 Policy클래스에 저장해둔다.
에피소드 종료 이후 저장해놓은 보상과 확률정보를 히스토리에서 역으로 꺼내면서 미분을 진행하고 모든 미분이 종료한 후 옵티마이저의 step함수를 이용해 \(\theta\)를 업데이트 시킨다.
9.3 액터-크리틱
액터-크리틱은 정책 네트워크와 밸류 네트워크를 함께 학습하는 방법이다.
Q 액터-크리틱(가장 간단한 방법) , 어드벤티지 액터-크리틱, TD 액터-크리틱 3가지 종류가 있다.
(1) Q 액터-크리틱
Policy Gradient 식은 다음과 같다.
그리고 이 공식을 베이스로 하여 REINFORCE 알고리즘 공식은 아래와 같다.
계산하기 어려운 \( Q_{\pi_{\theta}}(s,a)\) 대신 계산 가능한 \(G_t\)로 변경하였다.
하지만 Q엑터-크리틱에서는 Policy Gradient 공식의 Q를 그대로 사용하여 정책 최적화를 하려고 한다.
실제 \( Q_{\pi_{\theta}}(s,a)\)를 모르기 때문에,
CH08 가치기반 에이전트에서 살펴본 딥Q러닝 방식을 도입해 Q를 계산해낸다.
결국 이 방식을 구현하기 위해서는 ,
1) 정책 네트워크 \(\pi_{\theta}\) 필요 ==> 실행할 액션 a를 선택하는 액터
2) w로 파라미터화 된 밸류 네트워크 \(Q_w\) 필요 ==> 선택된 액션 a의 Q밸류를 평가하는 크리틱
(2) 어드밴티지 엑터-크리틱
위 공식은 Policy gradient 공식이다.
여기서 \(Q_{\pi_{\theta}}(s,a)\)를 살펴보자. Q밸류가 큰 값을 가지게 되면 또는 변동성이 심해지면 학습 성능이 떨어진다. 그 부분을 방지하기 위해 아래와 같은 방법을 도입한다.
빨간 박스 안에 수식의 의미는 다음과 같다.
\(Q_{\pi_{\theta}}(s,a)\)는 상태 s에서 액션 a를 실행하는 것의 밸류이고, \(V_{\pi_{\theta}}(s)\)는 상태s의 밸류이다.
따라서 \(Q_{\pi_{\theta}}(s,a) - V_{\pi_{\theta}}(s)\)의미는 상태s에 있는 것보다 액션a를 실행함으로 추가로 얼마의 가치를 더 얻게 되는지를 계산한 수식이다.
계산 결과값을 어드밴티지(advantage) \(A_{\pi_{\theta}}(s,a)\)라고 부른다.
이처럼 어드밴티지 A를 사용하여 policy gradient를 계산하면 분산이 줄어들어 훨씬 안정적인 학습이 가능하다.
실제로 어드밴티지를 활용하여 구현하려면 신경망이 모두 3가지가 필요하다.
- 정책함수 \(\pi_{\theta}(s,a)\)의 신경망 \pi
- 액션-가치함수 \(Q_w(s,a)\)의 신경망 w
- 가치함수 \(V_{\phi}(s)\)의 신경망 \(\phi\)
위 3가지 신경망을 모두 학습해야 한다.
밸류 네트워크 \(Q_w, V_{\phi}\)들은 모두 TD방식으로 학습한다.
어드벤티지 액터-크리틱은 Q 액터-크리틱에 비해 그라디언트 추정치의 변동성을 줄여줌으로 학습 효율에 이점이 있다.
(3) TD 액터-크리틱
어드벤티지 액터-크리틱는 구현을 위해서 3개의 신경망을 구성해야 하는 단점이 있다.
신경망의 수를 줄이기 위해 고안한 방법이 TD 액터-크리틱 이다.
\(V_{\phi(s)\) 신경망을 고려해볼 때 손실함수는 아래와 같다.
손실함수를 TD 에러(\(\sigma\))라고 부른다.
상태s 에서 액션a를 선택했을 때 손실함수 기댓값은 아래와 같이 구할 수 있다.
결과적으로 \(\sigma\)의 기댓값이 어드밴티지 A(s,a)이다.
즉, A(s,a)의 불편추정량이 \(\sigma\)이다.
의미를 풀어서 보면, \(\sigma\)값은 같은 상태s에서 같은 액션a를 선택해도 상태전이가 어떻게 일어나느냐에 따라 매번 다른 값을 얻게 된다. 이 값을 모아서 평균을 내면 그 값이 A(s,a)로 수렴한다는 의미이다.
결국, 어드밴티지 정책네트워크 식을 다음과 같이 변환할 수 있다.
결국 신경망은 Q밸류네트워크가 제외된 정책\(\pi\) 네트워크(C단계) 와 V밸류 네트워크(D단계) 2개로 구성하였다.
대신 정책네트워크 계산(C단계)과 밸류 네트워크 계산(D단계)시 \(\sigma\)가 포함되며 해당 값은 B단계에서 계산식을 통해 계산되어 상수가 된다.
새로운 하이퍼파라미터 n_rollout을 추가했다. 밸류네트워크가 평가를 대신해 주기 때문에 액터-크리틱 기반 방법론은 학습시 리턴을 필요로 하지 않는다. 따라서 리턴을 관측할 때까지 기다릴 필요 없이 하나의 데이터가 생기면 바로 네트워크를 업데이트 할 수 있다. 여기서 한 틱의 데이터 발생시 업데이트 할지, n틱의 데이터 쌓였을 때 모아서 업데이트할지를 나타내는 변수가 n_rollout 이다. 여기 예재에서는 10개 데이터가 쌓였을 때 네트워크를 업데이트 시킨다.
ActorCritic 클래스는 정책함수 pi와 가치함수 v를 가지고 있다.
가치함수는 학습시에 클래스 내부적으로만 사용되므로 메인에서 호출하지는 않는다.
정책함수 pi는 상태s를 인풋으로 받아 정책네트워크를 통해 액션별 선택 확률의 의미를 가지는 값들을 리턴한다.
이 확률 정보를 이용해 Categorical 클래스의 sample함수를 호출함으로 액션을 선택하고 환경 env에 전달함으로 다음스탭으로 이동하면서 다음상태값과 보상을 받는다.
여기서 나온 결과값을 ActorCritic 클래스의 버퍼에 n_rollout 만큼 저장해둔다. (여기서는 10)
n_rollout 만큼 데이터를 적재 후 train_net 함수에서 적재된 데이터를 꺼내어 학습을 진행한다.
ActorCritic 클래스의 pi함수는 정책 네트워크, v함수는 밸류 네트워크에 해당한다.
두 네트워크는 맨 아래 H1 레이어를 공유하도록 구현했다. 따라서 H1은 정책 네트워크 업데이트할 때, 밸류 네트워크 업데이트할 때도 항상 업데이트 된다.
make_batch함수는 텐서들을 리턴하기 전에 데이터를 적재했던 버퍼 data를 초기화하고 있다.
즉 버퍼는 batch size 만큼만 적재해서 학습에 사용하게 된다.
train_net 함수의 loss 변수에는 정책 네트워크의 손실함수와 밸류 네트워크의 손실함수를 더하여 한 번에 업데이트를 진행한다.
정책 네트워크 손실함수 : -torch.log(pi_a) * delta.detach()
밸류 네트워크 손실함수 : F.smooth_l1_loss(self.v(s), td_target.detach())
여기서 detach()함수의 용도를 살펴보면,
파이토치의 backward 과정에서 상수로 인식되어 backward 대상에서 제외(detach) 시키도록 하기 위한 용도이다.